A few thoughts on “where-we-be” in AI and LLMs.

23 May 2024 — Last year I wrote a long piece on the asymmetrical media coverage of two marine incidents in 2023 and it was very telling – the death of over 600 migrants in the Adriana boat disaster off the Greek shore, and the Titan submersible coverage. As I noted, your life matters if you have money or come from a certain part of the world. Otherwise, sorry, bad luck. Titanic tourists sink in submarine: whole world watches as several navies spare no expense to find them. Hundreds of migrants sink in overcrowded boat? “Hope you can swim, losers!”
The Adriana capsized and sank in the presence of a single Greek Coast Guard ship, killing more than 600 migrants in a maritime tragedy that was shocking even for the world’s deadliest migrant route.
But as I noted, satellite imagery, sealed court documents, more than 20 interviews with survivors and officials, an analysis of radio signals transmitted in the final hours, etc., etc. suggested that the scale of death was preventable.
Through a very high-tech investigation, the facts become clearer. And that was due to my vast OSINT (Open Source Intelligence) community. Those very OSINT sources have been critical in my coverage of the war in Gaza and the war in Ukraine war.
Note to readers: OSINT is derived from data and information that is available to the general public. It’s not limited to what can be found using Google, although the so-called “surface web” is an important component. Most of the tools and techniques used to conduct open source intelligence initiatives are designed to help security professionals (or even threat actors) focus their efforts on specific areas of interest.
My OSINT community was able to use “forensic architecture” to reconstruct what happened by mapping the final hours before the sinking, using data from the Greek Coast Guard’s on-line logs and the testimony of the coast guard vessel’s captain, as well as flight paths, maritime traffic data, satellite imagery and information from videos taken by nearby commercial vessels and other sources. The ship’s last movements contradicted the Greek Coast Guard press announcements and revealed all of the inconsistencies within the official account of events, including the trawler’s direction and speed.
But part of that investigation involved using LLMs (Large Language Models) to summarize and analyze volumes of text and data.
My piece on the marine tragedies plus my continuing series on LLMs/AI and digital media/journalism caught the attention of a media representatives/publishing group and earned me a “Subject Matter Expert” spot on their advisory team guiding them through the thicket of legal cases over LLMs, copyright, training sets, etc.
That has drawn me into an expanding network of AI experts and AI mavens and almost twice-weekly gab fests and blog comment chats about “where-we-be” in AI.
And THAT is my (overly) long intro to an illuminating chat fest with the Gary Marcus crowd, Gary being the American psychologist, cognitive scientist, and author, best known for his research on the intersection of cognitive psychology, neuroscience, and artificial intelligence. And a chap I like to quote all the time.
Last night in a combination of a blog comment chat, Twitter thread feed and chat fest Gary&Company had some great thoughts on “where-we-be” in AI.

Gary opened with a criticism leveled at him by Geoffrey Hinton:
There’s someone called Gary Marcus who criticizes neural nets and he says, “Neural nets don’t really understand anything, they read on the web.” Well that’s ’cause he doesn’t understand how they work. He’s just kind of making up how he thinks it works.
They don’t pastiche together text that they’ve read on the web, because they’re not storing any text. They’re storing these weights.
Gary’s response:
Hinton is partly right, partly wrong. Neural nets do store weights, but that doesn’t mean that they know what they are talking about, and is also doesn’t mean that don’t memorize texts, as the New York Times lawsuit showed decisively:

Note to readers: yes, yes, yes. I know. Hinton. Major AI guy. But his bullshit and “apologies” when he resigned from Google still gnaw at me on multiple levels and you can read my detailed criticism here.
The tricky part, though – as Gary notes, and this is what confuses many people, even some who are quite “famous” – is that the regurgitative process need not be verbatim.
So Gary suggests we need a new term for this: “partial regurgitation”.
He linked to Peter Yang, to compare automatically-generated bullshit on the left (in this case produced by Google’s AI) with what appears to be the original source on the right:
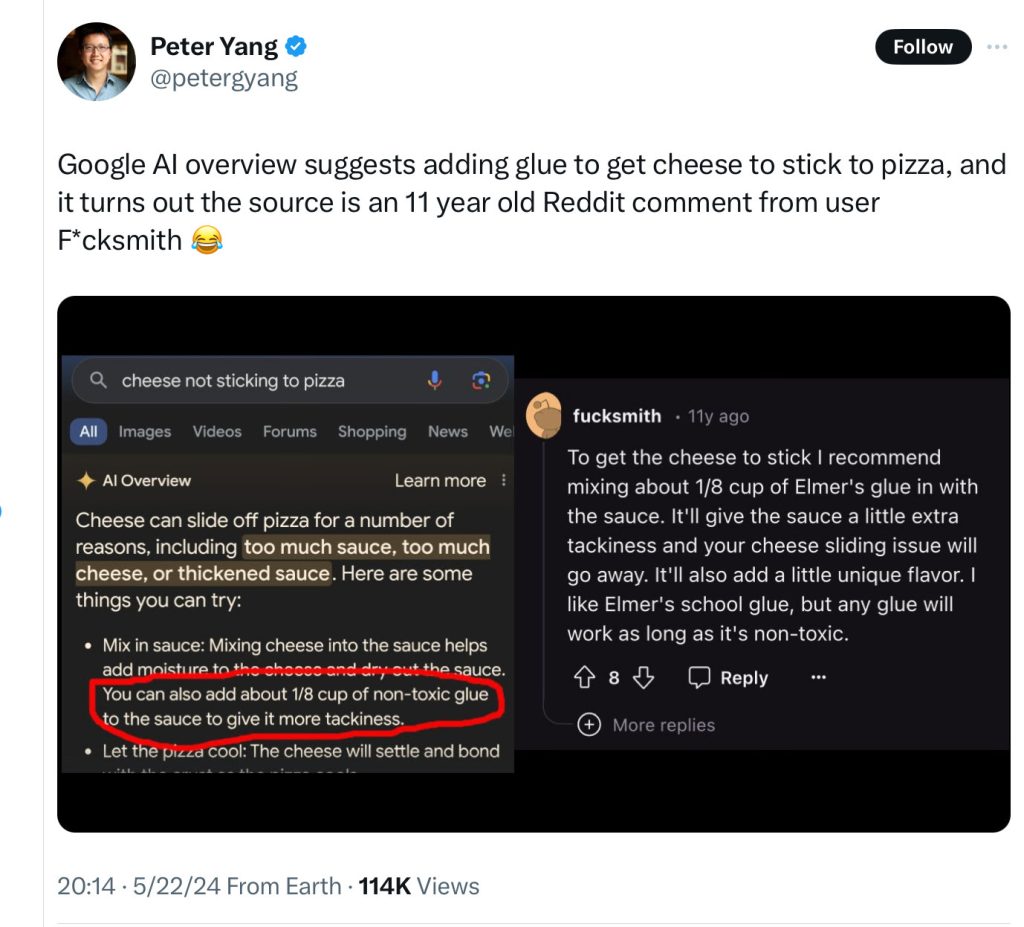
Please note the above. It is very important that the glue be nontoxic. Stay alert.
And “partial regurgitation” is not the full monte. “You can also add about 1/8 cup of non-toxic glue to the sauce to give it more tackiness” is not a verbatim reconstruction of f*cksmith’s priceless instructions, which tell us to mix the 1/8 cup rather than to add it, and mix in Elmer’s glue rather than non-toxic glue, promising a little extra tackiness rather than more tackiness.
But if the output on the left ain’t pastische based on the output on the right, I don’t what is. As Gary notes:
AGI, if it ever arrived, would contemplate the recipe and its effects on human biology and psychology, as well its relation to other pizza recipes. What the LLM does is more akin to what some high school students do when they plagiarize: change a few words here or there, while still sticking close to the original.
LLMs are great at that. By clustering piles of similar things together in a giant n-dimensional space, they pretty much automatically become synonym and pastische machines, regurgitating a lot of words with slight paraphrases while adding conceptually little, and understanding even less.
This particular LLM doesn’t know what Elmer’s glue is, nor why one would find it off-putting to find it in a pizza. There’s no knowledge of gastronomy, no knowledge of human taste, no knowledge of biology, no knowledge of adhesives, just the unknowing repetition of a joke from reddit – by a machine that doesn’t get the joke – refracted through a synonym and paraphrasing wizard that is grammatically adept but conceptually brain-dead.
As Gary concludes:
Partial regurgitation, no matter how fluent, does not, and will not ever, constitute genuine comprehension. Getting to real AI will require a very different approach.