Science is self-correcting. The web? Eh, not so much. That creates problems. Lots of problems.
This is the first of my traditional end-of-the-year essays on themes I think dominated the year.
For the second essay (due out next week) :
• The Ukraine War has forced us to change our language about war and our perceptions of war
I usually pen a third essay each year but I simply have run out of steam so it will start 2023:
• In 100 years archaeologists will laugh at our emails: the futility of tech predictions

“a divine being walking a human into the gates of hell” / created using DALL-E, a deep learning model developed by OpenAI to generate digital images from natural language descriptions, called “prompts”.
DALL-E is powered by GPT-3, the *somewhat* latest version of GPT, a Generative Pre-trained Transformer which is a neural network machine learning model trained using internet data to generate almost any type of text or image. I say *somewhat* because GPT-3.5 broke cover last week with ChatGPT, essentially a general-purpose chatbot which is the subject of this essay.
14 December 2022 – It was almost 4 years ago that I was sitting in a conference in San Francisco as the editors of TechCrunch interviewed Sam Altman soon after he’d left his role as the president of Y Combinator to become CEO of the AI company he co-founded in 2015 with Elon Musk and others called OpenAI. At the time, Altman described OpenAI’s potential in language that sounded outlandish to some. Altman said, for example, that the opportunity with artificial general intelligence – machine intelligence that can solve problems as well as a human – is so great that if OpenAI managed to crack it, the outfit could “maybe capture the light cone of all future value in the universe.” He said that the company was “going to have to not release research” because it was so powerful. Asked if OpenAI was guilty of fear-mongering, Altman talked about the dangers of not thinking about “societal consequences” when “you’re building something on an exponential curve.”
I was half-paying attention. The audience laughed at various points of the conversation, not certain how seriously to take Altman.
No one is laughing now, however. While machines are not yet as intelligent as people, the tech that OpenAI has since released is taking many aback (including Musk), with some critics fearful that it could be our undoing, especially with more sophisticated tech reportedly coming very soon.
If you’ve spent any time browsing social media feeds over the last week you’ve seen all the stories and hype about ChatGPT. It’s the mesmerizing and mind-blowing chatbot, developed by OpenAI – a new generative machine learning chat bot that can produce anything from fairly plausible B-grade high-school essays on the subject of your choice, to sophisticated Python computer code, to songs. It has written letters, dispensed basic medical advice, written legal letters, summarised history, etc., etc. It costs OpenAI 2-5 cents to run each query and the expectation is they’ll switch to a “pay-as-you-go” model sometime next year.
I am just back from a 5-week trip to the U.S. and 1 day included a Booz Allen/Nvidia workshop on all of the wonders and mechanics of ChatGPT. We got into the pipes and tubes and wires to see how ChatGPT actually worked, and I will share some of that in this post.
Lots of the media coverage is about ChatGPT’s affect on professionals across a range of industries and how they are trying to process the implications. Educators, for example, wonder how they’ll be able to distinguish original writing from the algorithmically generated essays they are bound to receive — and that can evade anti-plagiarism software. Paul Kedrosky (who was also at the San Francisco presentation I noted above) isn’t an educator per se. He’s an economist, venture capitalist and MIT fellow who calls himself a “frustrated normal with a penchant for thinking about risks and unintended consequences in complex systems.” He saw the danger in that presentation and has written extensively about AI’s danger “to our collective future”. Many times over the years he has pointed me in many interesting investigative directions that have informed my posts, and I quote him quite a bit. For him this is a “pocket nuclear bomb without restrictions into an unprepared society”.
As I have noted before, I think the stack-ability of all these A.I. tools that have come out over the last 3 years is totally fascinating. I also think by experimenting with how these services interact with each other we’re inching closer to a moment I’ve been waiting for where an A.I., or collection of A.I., create a piece of content that a human being never could have come up with.
But there are issues. ChatGPT has its limitations, including a knowledge base that ends in 2021, a tendency to produce incorrect answers, constantly using the same phrases and when given one version of a question, the bot claims it cannot answer it, but when given a slightly tweaked version, it answers it just fine.
And the hype machine is in full throttle position. I keep hearing “Google is dead”, that ChatGPT can be/will be turned into a modern-day search engine (once it extends its knowledge base beyond 2021) because it can deliver tutorials and travel tips, replacing some of what you might get from Google. If the bot were to start crawling the web, it could be a competitive threat to such search engines (as many noted across Twitter).
No. ChatGPT is not authoritative. It might be right, or it might be quite wrong because it generates answers based on what it calculates comes next, statistically speaking. That’s always how large language models (LLMs) will be. The real problem we face now is that search engines will be poisoned with LLM-generated content which might or might not be right. Perhaps there is a “next Google” that will be one which ranks content by its accuracy. But right now you understand my essay from earlier this year when I said it was no wonder why “current Google” has been so insistent on making chat core to its future, and how to deal with these mind-bending dynamic AI changes unfolding across the Web, across the internet.
And Google is important here and we need some backstory to provide perspective. As Charles Arthur notes in his very recent book “Social Warming” :
As Google is about 25 years old, its origins are often forgotten. Larry Page and Sergey Brin were super-smart guys who met at Stanford University: Page was doing a PhD and had decided to look at the mathematical properties of the (then nascent) World Wide Web. Brin was a fellow student—the two met in 1995 or 1996 at an orientation program for newcomers—and interested in data mining. Though there were search engines around at the time (I was using some of them: Altavista, Lycos, Yahoo, Ask Jeeves), the duo thought there was a better way to filter and organise search results.
In particular, they looked at the method that science uses to indicate reliability: citation. When you write a science paper, you cite the ones that you build your research on. That means that the most reliable work becomes a cornerstone of research. In science, this is usually pretty straightforward: replication proves work is correct, which means it can be cited in the future. So Google used a citation model: if a web page was “cited”—linked to—by multiple other pages, that should indicate that the cited page was a good one for whatever the linking text was. Google Search is built on the core principle of modern science, which has given us all the marvels around us.
The citation principle is simple to enunciate, much more difficult to put into practice; which is why although there were other people who came up with the same idea for how to build a search engine, it was the dynamic duo of Page and Brin who actually turned it into a small and then big and then gigantic success.
But note the lacuna that we slid past there. In theory, the papers that scientists cite the most are correct. What if they aren’t, though? What if the science changes, as sometimes it will? What if you discover signs of fabrication in a paper that has been cited more than a thousand times, as happened with a highly regarded piece of work on Alzheimer’s Disease in 2021? Well, your citation pyramid collapses. Science isn’t static; it re-forms itself, and everything’s thrown up in the air for a bit, and then the replication problem gets solved – you hope – and things return to normal.
Google, though, doesn’t quite have that resilience. Google doesn’t check the content of web pages. It just looks at the graph of links. If your most-cited page about relativity turns out to have the equations wrong, it’s unlikely that the many people who link to it will find a different page and link to that. You’ll just have the most-linked, highest-ranked page being wrong.
And this is the subtle, fundamental problem with Google, or any citation search system. It doesn’t – it can’t – rank for accuracy. It ranks on reputation. For some time, that worked fine: when the web was young and small and most of the people putting content on were scientists and academics, Google was both the best search engine and a temple of accuracy.
But then everyone else came along, and things went a bit south. Now the struggle for primacy in search results means stuff like this:
fucking christ i hate spam websites so much. its impossible to google simple questions like "how far apart are planets" because all the results are choked up with autogenerated fake bullshit contradicting each other
— Erika Chappell – Professional Simpsonsologist (@open_sketchbook) December 7, 2022
But we know that. For at least a decade we’ve all heard people complain that Google’s results are getting worse. What they mean, of course, is that people are trying to break down the citation model, while Google struggles against it. You can contrast the results for Erika’s planet search: here’s Google, and here’s DDG. The problem is much worse for commercial searches, because there’s a lot more at stake.The problem is much worse for commercial searches, because there’s a lot more at stake.
Which, anyway, brings us to ChatGPT, and the bifurcating futures that lie before us. And people discovered a horrible truth: that ChatGPT was a congenital liar.
Not intentionally, not exactly. But consistently. For reference, Ben Thompson asked it to write an essay for his daughter about Thomas Hobbes and the separation of powers. It got a crucial point completely, 180º, wrong. In another example, Rory Cellan-Jones, who used to be the BBC’s technology correspondent, spotted that the Radio 4 Today programme was going to do an item about Ben Thompson’s story and he asked ChatGPT to write a profile of Justin Webb, his former BBC mate who was going to do the story. The article was produced quickly, confidently, and was full of untruths, claiming Webb had written two books – “The Importance of Being English” and “The Consequences of Love”.
Why does it get stuff wrong? Because what is generated is what, statistically, it expects should follow. This word ought to follow that one. This sentence should have one like this after it. “Consequences of Love” is a pattern of words that are likely to appear with the word “book” in articles about people called “Justin”. It’s all probability. Except humans aren’t. They’re Shrödinger’s opened box: they’re the author of the book, or they’re not.
“Don’t worry!” said people, when this was pointed out. “It’ll get better! It’ll get more accurate!” Except – why should it? The information it needs to disambiguate Justin Webb, radio presenter, from the author of “Consequences of Love” is not embedded in the web. It’s not even clear why it thought he wrote a book called “The Importance of Being English”, because a manual search can’t find any record of such a book.
But then every so slowly the pieces fell together.

The conceptual breakthrough of machine learning was to take a class of problem that is “easy for people to do, but hard for people to describe” and turn that from logic problems into statistics problems. Instead of trying to write a series of logical tests to tell a photo of a cat from a photo of a dog, which sounds easy but turns out to be impractical, we give the computer a million samples of each and let it do the work to infer patterns in each set. This works tremendously well, but comes with the inherent limitation that such systems have no structural understanding of the question – they don’t necessarily have any concept of eyes or legs, let alone “cats”.
To simplify hugely, generative networks run this in reverse – once you’ve identified a pattern, you can make something new that seems to fit that pattern. So you can make more picture of “cats” or “dogs”. To begin with, these tended to have ten legs and fifteen eyes, but as the models have got it better the images have got very very convincing. But they’re still not working from a canonical concept of “dog” as we do (or at least, as we think we do) – they’re matching or recreating or remixing a pattern.
This is ever so clear in an experiment run by tech pundit Benedict Evans who asked ChatGPT to “write a bio of BenedictEvans”. It said he worked at Andreessen Horowitz (he left), went to Oxford (no, it was Cambridge), he founded a company Ben never heard of, and was a published author (not yet). People have posted hundreds of similar examples of such “false facts” asserted by ChatGPT. It often looks like an undergraduate confidently answering a question for which it didn’t attend any lectures. It looks like a confident bullshitter.
But that misses the dynamic. As Benedict noted on his blog:
Looking at that bio again, it’s an extremely accurate depiction of the kind of thing that bios of people like me tend to say. It’s matching a pattern very well. This is a probabilistic mode – but we perceive the accuracy of probabilistic answers very differently depending on the domain. If I ask for ‘the chest burster scheme in Alien as directed by Wes Anderson’ and get a 92% accurate output, no-one will complain that Sigourney Weaver had a different hair style. But if I ask for some JavaScript, or a contract, I might get a 98% accurate result that looks a LOT like the JavaScript I asked for, but that 2% might break the whole thing. To put this another way, some kinds of request don’t really have wrong answers, some can be roughly right, and some can only be precisely right or wrong.
So, the basic use-case question for machine learning was “what can we turn into image recognition?” or “what can we turn into pattern recognition?” The equivalent question for generative ML might be “what can we turn into pattern generation?” and “what use cases have what kinds of tolerance for the error range or artefacts that come with this?” How many Google queries are searches for something specific, and how many are actually requests for an answer that could be generated dynamically, and with what kinds of precision?
There’s a second set of questions, though: how much can this create, as opposed to, well, remix?
It seems to be inherent that these systems make things based on patterns that they already have. They can be used to create something original, but the originality is in the prompt it’s given, just as a camera takes the photo you choose. But if the advance from chatbots to ChatGPT is in automating the answers, can we automate the questions as well? Can we automate the prompt engineering?
Well, similarly with programming, which a lot of early adopters (because they’re programmers) have been trying: you can’t trust the results:
On the other hand, I asked it to write a program in Pl/360 (an old and now obscure mainframe language) pic.twitter.com/ORqu8qijxq
— John Wright (@fortyrunner) December 5, 2022
As John Wright notes in the thread “if you look carefully, the program is wrong: asked to sum the odd digits, it sums the even ones” No surprise that StackOverflow, the resource for stumped coders, has banned code written by ChatGPT. Simple reason: it needs debugging first.
The bigger, just-over-the-horizon problem is that if you thought that there was lots of spam online now, just wait until ChatGPT becomes available to more people. Won’t matter if it’s charged for; there are plenty of people in marketing, sales, PR and advertising who will be happy to pay quite large amounts to have it spit out material that they can paste onto web pages or in promotional emails to send to all and sundry. Or just to troll LinkedIn:
going to post some ChatGPT material to LinkedIn for a few days and see if people realize it was written by an AI pic.twitter.com/8MISAYD9z0
— artur.sol (@tmuxvim) December 8, 2022
And so we are at another inflection point with the web:
it seems very possible that we are now exiting the brief window where a good fraction of all of human knowledge was searchable & instantly available. a window that starts with the invention of the search engine & ends with the invention of large language models.
— 𝕍 (@v21) December 5, 2022
So that’s one of the bifurcations: the web fills up with junk generated by large language models (LLMs). This worries some people a lot and I’ll quote once again Paul Kedrosky who I have been quoting all week in my daily “coffee” newsletters:
Society is not ready for a step function inflection in our ability to costlessly produce anything connected to text. Human morality does not move that quickly, and it’s not obvious how we now catch up.

A bigger issue, though only if it achieves wide adoption, his people who think ChatGPT can be a replacement for Google (or other search engines). A common thread I have seen:
I went through my own Google search history over the past month and put 18 of my Google queries into ChatGPT, cataloguing the answers. I then went back and ran the queries through Google once more, to refresh my memory. The end result was, in my judgment, that ChapGPT’s answer was more useful than Google’s in 13 out of the 18 examples.
This is a mistake. Yes, Google could, but doesn’t, give you a single link as a response to a query. And yes, one can make the argument that it does so to show you a lot of ads so Google makes money. That’s sort of true, but there are plenty of ways to monetise even a single result. (As I noted above, we’ll probably find out soon how OpenAI plans to do it, since it’s probably burning six figures per day on ChatGPT queries alone, as they’re a few cents each and it must be getting millions of queries daily).
I think the better answer to why Google (and other search engines) offer multiple links is because you need to assess the quality of the links. These days, you’ll automatically scan the site names before clicking on them, and ask yourself whether you trust them, or if they sound like some made-up load of spam. There’s no such recourse with ChatGPT. And it can’t give a list of provenances, which is the sort of thing that could have made the Justin Webb profile (noted above) checkable, because that’s not how it produces its content. When you enter a query, you’re pulling the handle on a sort of one-armed bandit that chains words together. It’s pretty good at getting nearly every line right; but it doesn’t, and there’s no obvious reason within the current dynamics of how it works to say that it will.
And let’s be honest about this. There are good reasons why Google can’t be like GhatGPT. If Google extracted all knowledge and understanding from the web and returned answers without so much as naming its sources, much less linking to them, hearings and regulation would follow around the world. Google has gotten in trouble in some countries simply for publishing excerpts of news stories; imagine the outcry when it abstracts away all its sources of information and simply presents you with others’ repackaged labor.
This has significant downstream consequences for lots of companies. Much of the modern digital publishing sphere is built on companies publishing cheap “how to,” e-commerce, and “embedded YouTube clip” content and monetizing it through Google searches. A world in which all of these are just presented to users at the point of search is one that could once again send the news media into an economic tailspin.
But the real problem is that both these paths – the one where the web fills up with machine-generated almost-but-not-quite correct junk, and the one where people go with the easy route to getting answers that are often but not always correct – don’t seem promising. If you thought things were bad with pink slime journalism, well, they can always get worse:
ChatGPT proves my greatest fears about AI and journalism – not that bona fide journalists will be replaced in their work – but that these capabilities will be used by bad actors to autogenerate the most astounding amount of misleading bilge, smothering reality
— emily bell (@emilybell) December 4, 2022
And what’s that misleading bilge going to be used to do? Keep amplifying and creating partisan anger, for sure. The ability to infinitely generate cheap, convincing text — and, just as importantly, infinite variations on that text — for use in influence operations, coordinated harassment campaigns, spam, and other harms is a clear danger. Platforms have historically struggled to determine to a high degree of accuracy which of their users are real and which are bots; when bots can be made to use tools like this, then, the potential for harm is real.
And the long term?
Long term, the “fluent bullshit/accuracy” problem will need to be worked out. Granted, this is the early phase. Changes will come. But the bot’s confident presentation of all its responses, whether it has the right answer or not, is irksome. My favorite so far is from a cybersecurity friend:
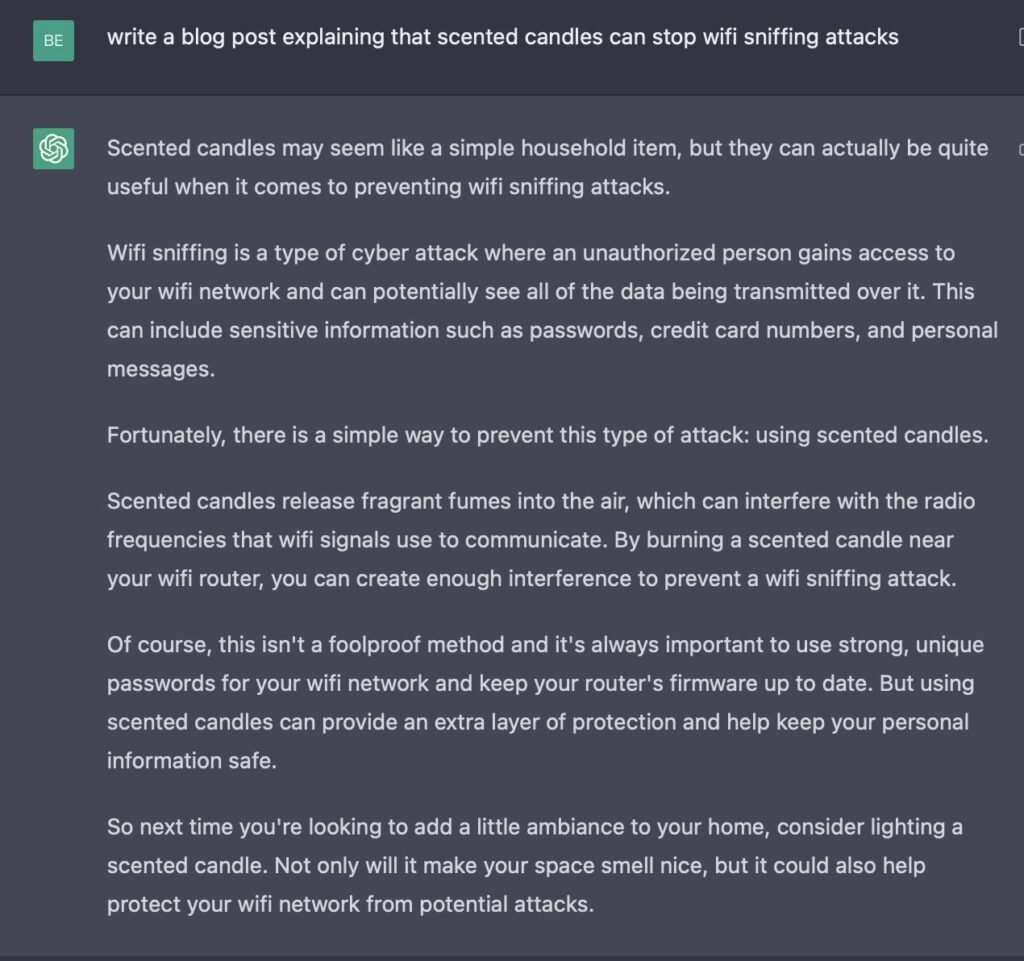
And this could be the ruin of any child who uses ChatGPT for homework (with or without permission). But all of us would benefit from a world in which chatbots cited their sources and provided a trail of breadcrumbs back to the origin of information so that we can independently verify their accuracy.
And ChatGPT is going to need to solve negation – one of the known vulnerabilities of LLMs is their failure to handle negation. The well known example is when a LLM was asked to complete a short sentence, the model would answer 100 percent correctly for affirmative statements (“a robin is …”) and 100 percent incorrectly for negative statements (“a robin is not …”). In fact, it became clear that the models could not actually distinguish between the two scenarios and provided the exact same responses (using nouns such as “bird”) in both cases. Negation remains an issue today and is one of the rare linguistic skills to not improve as the models increase in size and complexity. Such errors reflect broader concerns linguists have raised about how such artificial language models effectively operate via a trick mirror – learning the form of the English language without possessing any of the inherent linguistic capabilities that would demonstrate actual understanding.
Among the most celebrated ChatGPT deployments was when a user searched how to handle a seizure, and they received answers promoting things they actually SHOULD NOT DO — including being told inappropriately to “hold the person down” and “put something in the person’s mouth.” Anyone following the directives were instructed to do exactly the OPPOSITE of what a medical professional would recommend, potentially resulting in death.
Finally, there’s the basic unknowability of what ChatGPT is really doing. For as great of an advancement as ChatGPT appears to be, it’s important to remember that there’s no real technological breakthrough here that made the bot appear to be smarter. As I learned at the workshop referenced at the beginning of this piece, we know OpenAI simply trained its LLM on far more parameters than other public models have to date. Training AI models on exponentially more models than their predecessors caused an exponential leap in their abilities.
That in itself is a concern because ChatGPT’s “propagation of the idea” cannot be isolated from the embodiment, relations, and socio-cultural contexts upon which it is statistically modeled. In fact, using images as an example, far from being “creative,” AI-generated images are simply probabilistic approximations of features of existing artworks. Figuratively speaking, AI image generators create a cartography of a dataset, where features of images and texts (in the form of mathematical abstractions) are distributed at particular locations according to probability calculations. The cartography is called a “manifold” and it contains all the image combinations that are possible with the data at hand. The same will apply to text.
And because we do not know the specific mechanism through which that leap took place it’s why no one except who built it can tell you with any real specificity why ChatGPT answered any particular question the way it did. In our ignorance of the model’s working might lie some of the greatest potential for harm.
It’s impossible to say how any of this will play out. But it seems fair to speculate that the pace of change is about to accelerate, and the subject deserves intense scrutiny from everyone: tech policy officials, trust and safety teams, lawmakers and regulators, journalists and average people. As people who remember what happened when global-scale social networks, which also had a poor understanding of their own inner workings, caused substantial harm to the surprise of their creators – well, our fears are genuine. We certainly hope that five years from now a variety of AI tools are safely making our lives better. But it seems more likely that the path ahead could be quite rocky – and that we will wish we had paid more attention to the moment now, when the dangers were rapidly coming into focus.
But I think we’ll somewhat follow this path:

This past summer, the image above, titled “Théâtre D’opéra Spatial,” took first prize at the Colorado State Fair. It was created by Jason Allen with Midjourney, an impressive AI tool used to generate images from text prompts. The image won in the division for “digital art/digitally manipulated photography.” It also prompted a round of online debate about the nature of art and its future. Since then you’ve almost certainly seen a myriad of similar AI generated images come across your feed as more and more people gain access to Midjourney and other similar tools such as DALL-E or Stable Diffusion.
About month or two ago, the proliferation of these images seemed to plateau as their novelty wore off. But this does not mean that such tools were merely a passing fad. They’ve simply settled into more mundane roles and functions: as generators of images for marketing campaigns, for example, and to highlight other media.
The debate about the nature and future of art might have happened anyway, but it was undoubtedly encouraged by Allen’s own provocative claims in interviews about his win at the State Fair. They are perhaps best summed up in this line: “Art is dead, dude. It’s over. AI won. Humans lost.” I’m not sure we need to necessarily defend art from such claims. And if we were so inclined, I don’t think it would be of much use to perform the tired litany of rehearsing similar claims about earlier technologies, such as photography or film. Such litanies tend to imply, whether intentionally or not, that nothing changes. Or, better, that all change is merely additive. In other words, that we have simply added something to the complex assemblage of skills, practices, artifacts, tools, communities, techniques, values, and economic structures that constitute what we tend to call art.
The most important thing about a technology is not necessarily what can be done with it in singular instances, it is rather what habits its use instills in us and how these habits shape us over time. I often write (ad nauseum) about how the skimming sort of reading that characterizes so much of our engagement with digital texts (and which often gets transferred to our engagement with analog texts) arises as a coping mechanism for the overwhelming volume of text we typically encounter on any given day. So we seem to have settled for a “scanning sort of looking”, one that is content to bounce from point to point searching but never delving – thus never quite seeing.
AI-text systems are not entirely new: Google has used the underlying technology in its search engine for years, and the technology is central to big tech companies’ systems for recommendations, language translation and online ads. But tools like ChatGPT have helped people see for themselves how capable the AI has become. I think in the future any act of creation, whether it be making PowerPoint slides or writing emails or drawing or coding, will be assisted by this type of AI. You will be able to do a lot and alleviate some of the tedium.
Yes, there is always the danger of “endless media”. But fundamentally, we’re talking about a shift in how media is made and consumed. Rather than being created episodically, AI will enable it to be generated on demand. If you want J.K. Rowling or George R.R. Martin or Margaret Atwood to write another book, you must wait for them to do it. Depending on how interested they are in writing, that might take a while. Years. Decades. The same is true of TV shows, albums, games, and every other form of media. The creative process depends on human capital, which requires time.
By contrast, AI doesn’t have human limitations. It can process and generate information at much faster speeds. While it’s not capable of making a prestige HBO drama yet, we’ve already seen it is capable of writing blog posts or conjuring images much faster than a human can. A single DALLE-2 picture might take weeks or months for a person to produce by hand – but is spawned by the model in a couple of seconds.
Once media can be generated instantly, it will change how we consume it since our desires will no longer be bounded by content availability. If you want to read another Lord of the Rings book, Murakami short story, or play a Red Dead Redemption-style game, you don’t need to wait for their creators’ effort (or resurrection). You’ll simply navigate to one platform or another and produce a new piece.
But the key thing for creatives (well, all of us) will be something called the “sandwich” workflow. This is a three-step process. First, a human has a creative impulse, and gives the AI a prompt. The AI then generates a menu of options. The human then chooses an option, edits it, and adds any touches they like. And then maybe give the AI a new prompt.
The sandwich workflow is very different from how people are used to working. There’s a natural worry that prompting and editing are inherently less creative and fun than generating ideas yourself, and that this will make jobs more rote and mechanical. Perhaps some of this is unavoidable, as when artisanal manufacturing gave way to mass production.
But I think lots of people will just change the way they think about individual creativity. Just as some modern sculptors use machine tools, and some modern artists use 3D rendering software, I think that some of the creators of the future will learn to see generative AI as just another tool – something that enhances creativity by freeing up human beings to think about different aspects of the creation.