I write a lot about the minutiae of the digital advertising industry. Herein a few random, “Big Picture” thoughts following my last [sigh] pilgrimage to the annual Cannes advertising conference as I ended my days on the conference circuit.
This will be part of my updated monograph on the digital advertising industry.
29 August 2022 – – As my regular readers know, I have been very fortunate in my career path. A very long time ago (or as Billy Joel once sung “when I wore a younger man’s clothes”), I ended up on Wall Street at Salomon Brothers as a currency trader after college. Funny where that junior degree in physics and all that math can take you. That segued to a role as a mergers & acquisition analyst at Salomon (they were expanding like crazy).
After 3 years on The Street I went to law school … and came back to The Street, to land at Cleary Gottlieb Steen & Hamilton. How long ago? George Cleary, Leo Gottlieb, Mel Steen and Fowler Hamilton were still alive and they had their own special wing in the office. Fowler Hamilton often came into the office canteen to get his own coffee. Alton Peters (a partner and husband of one of Irving Berlin’s daughters) had Irving Berlin’s Oscar for “White Christmas” on a special table, all lit up.
I was the most fortunate of young men. I came under the tutelage of senior partner Walter Rothschild. He did not want his staff sitting in their offices all the time. He continually sent us out to spend time with the client, to understand how a company is run, how markets work, etc. To “get in the trenches” so that we saw how the legal work we did affected (or did not affect) the business. So we did not think and act in a vacuum.
I got lucky. I spent a good chunk of my time at Ogilvy, the New York City-based British advertising, marketing, and public relations agency (which is now part of the WPP Group, the largest advertising and public relations companies in the world). It enabled me to learn the advertising business and allowed me to see the very beginnings of e-commerce and consumer data analysis which has informed so much of what I write about. I eventually worked for the firm.
The 1970s. What heady times. The Beatles broke up, political crises were building (today’s headlines are hardly an anomoly), and the government put a ban on cigarette advertisements. It wasn’t until the mid-1970s when advertising companies really starting bringing in some serious money. And by the end of the 1970s, the advertising business was raking in the money.
I looked up an American Association of Advertising Agencies report for that time (an organization that has been around since 1917) which noted that by 1975 consumers were exposed to up to 1,600 ads a day. TV programming was now completely in color (actually as of 1972 in the U.S.) and sales of color TVs finally outpaced B&W – and television became the most sought-after medium for advertising. Television ads reached about $6 billion, in 1976 alone.
And while the 1960s became famous for the creative revolution, the 1970s brought about different ways of thinking. The use of computers skyrocketed in the 1970s, changing the way agencies did their everyday operations: billings, reporting, and more importantly – research. Technology helped agencies gather more detailed information, such as demographics, to analyze consumers, make projections and develop positioning for brands based on consumer behavior and perception. It was the birth of full-on consumer data analysis.
And 1970’s advertising switched the focus from very to-the-point messaging, to more emotional approaches, sometimes to a fault. One of the most frowned-upon practices of 1970’s advertising was subliminal messaging. I am sure many of you have read the stories about sexually charged words and photos hidden in ice cubes, the folds of clothing, anywhere to get the target audience to associate the brand with innate desires. Advertising executives faced lots of criticism because of these practices, and consumers began to grow skeptical of advertising. Due to the vast array of skepticism, the Federal Trade Commission and the National Advertising Review Board created the first standards that advertising companies had to follow.
And e-commerce was born – the phrase first used in 1979 and regularly cited by 1982.

Ah, the simple days. In the beginning, e-commerce was very utilitarian. You knew what you wanted before you turned on your PC, you clicked on it and you bought it. The first really successful organizing layer on top of the web, search, was also very utilitarian and, of course, so was the first big online advertising model, which was explicitly based on search. But ever since then, e-commerce, discovery and advertising have been moving and expanding across the spectrum – expanding from utility to experience, and from search and lists to suggestion and discovery.
The global advertising business is now worth about $600bn a year, and at least half of that (and growing) is digital. A huge chunk of this is now being changed (not overturned), due to regulation – like the GDPR and the CCPA – on one side, and the duopoly platform companies (Chrome, iOS) on the other. Cookie-based, cross-site, third party tracking will disappear (in some manner), as is some of the related tracking that had been built into iPhones such as the Identifier for Advertisers (IDFA) which is a random device identifier assigned by Apple to a user’s device.
Yes, you can advertise based on what’s on the page (“context”), and you can advertise based on what else someone did on your site (“first party”), but advertising based on what someone did on another site (3rd party, those bloody cookies) is going to look totally different. What does that mean? How different? No one quite knows. It’s all fluid, something-in-progress.
What we have seen in recent years is significantly enhanced information sharing and networking capabilities among smartphone users, advanced by geospatial technologies which have undeniably permeated almost all aspects of modern life in our society. Social media apps are increasingly location-based, providing analysts with access to a wide range of shared spatial data, such as check-ins, geo-tagged images, video clips or text messages, or reviews of businesses and other localities.
Today, click on a link to an article on a news website. If you have a fast internet connection, you’ll see the article almost immediately, but the slots for adverts will usually remain empty for another second or two. The ads which then appear aren’t generally chosen in advance. Instead, a near instantaneous, automated auction of each slot goes on behind the scenes to determine which ad you will be shown. Your phone or laptop may itself be gathering bids for the auction. Sometimes, an enigmatic pattern or grey rectangle will appear instead of an ad.
What goes on during those few seconds is vital to the economics of advertising and journalism and is the subject of sharp, subterranean conflict among news publishers, the big online platforms (especially Google), and independent providers of “AdTech”, the technology of digital advertising. Sales of print newspapers have been falling for years, and revenues from online subscriptions alone are generally insufficient to support large-scale news reporting. So advertising income matters.
For instance, British newspapers were making £4.6 billion a year from print advertising as recently as 2007, but by 2017, according to the consultancy Mediatique, earnings had fallen to £1.4 billion. Online advertising, by contrast, has boomed, but the revenue has largely bypassed news publishers. Less than 5 per cent of online advertising money in Britain is spent on ads that appear on newspaper websites, and the resulting revenue for newspapers (£487 million in 2017, Mediatique says) falls well short of making up for the decline in print advertising.
New data just released (in July 2022) by the Bureau’s Service Annual Survey shows U.S. newspaper publishers collected about $22.1 billion in revenue in 2020, less than half the amount they collected in 2002.
One way for an advertiser or advertising agency to get their ads onto a news website is by striking a direct deal with the site’s publisher, at a fixed price per thousand “impressions” (each time an ad is shown to a viewer counts as one impression). But an advertiser can also buy ad slots, often far more cheaply, in what they call “open auctions” or the “open marketplace”. There, demand from multiple advertisers is brought together electronically with supply from any website whose content carries ad slots (news publishers are distinctly in the minority in the open marketplace). Each ad slot is auctioned separately, and its price is influenced not just by the quality of the website – which often matters less than one might hope – or by the nature of the content surrounding the slot, but by what, if anything, is known about the user to whom the ad will be shown in a couple of seconds’ time.
Prices in these auctions are usually very low: the winning bid for an ad slot will normally be no more than a fraction of a penny. But fractions of pennies add up when earned many, many times over. For example, I’m told by a friend that works at the Guardian in London that the Guardian gets about a billion online ad impressions every month, which brings in £50-£70 million a year, somewhere between a fifth and a third of the paper’s total revenue. Without that, its newsroom would be gutted.
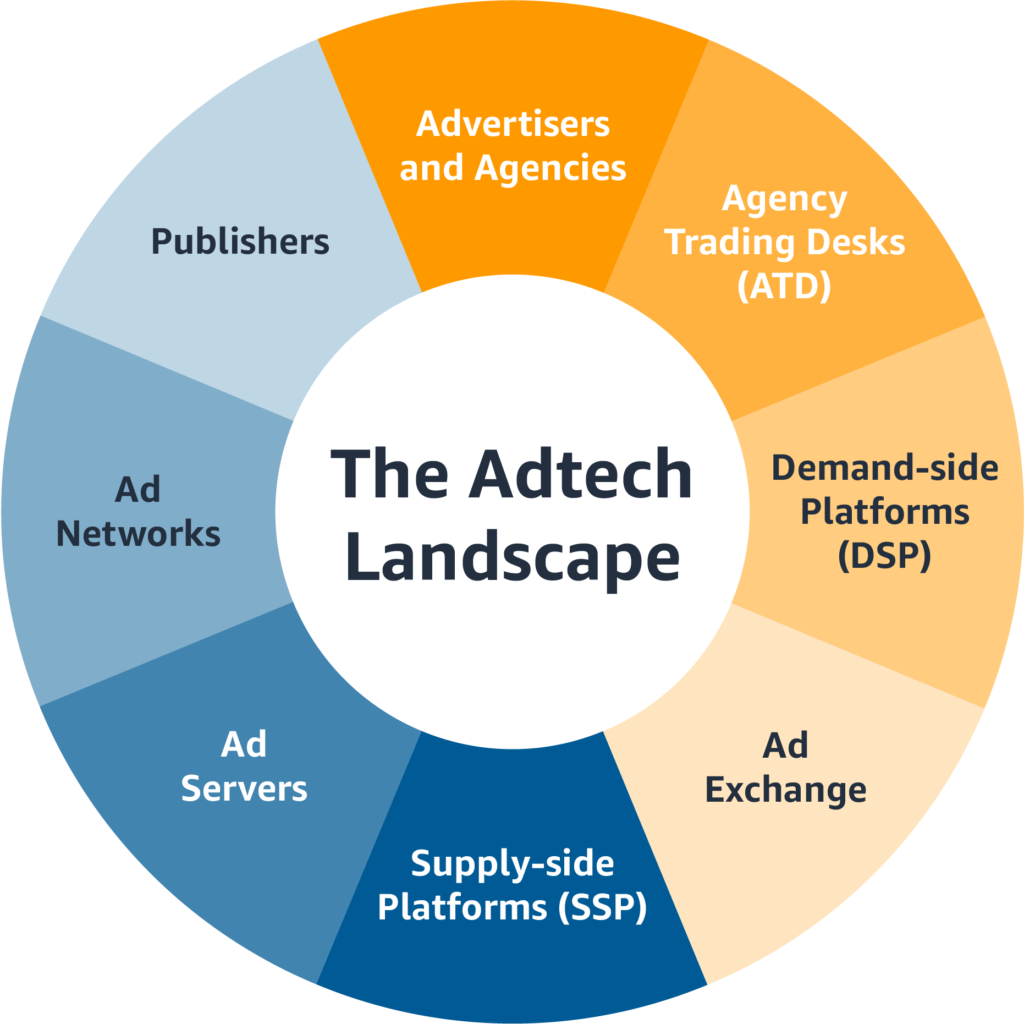
The biggest host of instantaneous auctions by volume is Google’s ad exchange, but news publishers and other big providers of online content also bring their supply of ad slots to market through AdTech systems known as “supply-side platforms” or SSPs. Each SSP pumps out to potential buyers a “bid stream” of individual, momentary opportunities to show an ad in a specific slot on a particular site. These bid streams amount to a Niagara Falls of ad slots, bought and sold via what participants call the “programmatic pipes”: a global digital infrastructure of datacentres, AdTech platforms and fibre-optic cables.
To process the torrent flowing through the pipes and assess each and every ad slot – whether it is worth bidding for, and if so how much it is worth – is very demanding. Most advertisers and ad agencies, instead of building a system to do it themselves, contract out the job to a “demand-side platform”. A DSP might have to process tens of millions of ad opportunities a second, and will have only about a fifth of a second to respond to each opportunity: if it takes longer than that, it is simply timed out of the auction for that slot.
The programmatic pipes are technologically impressive but economically opaque, leaking money in ways that are hard to trace. In 2016, both the Guardian and the New York Times experimented by bidding for ad slots on its own website, and discovered that sometimes only 30 per cent of what it paid found its way back to the newspaper. Lots of hands in the stream.
NOTE TO MY READERS: a couple of years later, a team from PricewaterhouseCoopers was commissioned by the Incorporated Society of British Advertisers to follow the money through the pipework more systematically. The team worked with fifteen huge advertisers – including Nestlé, Unilever, Vodafone and British Airways – whose aggregate annual expenditure on online advertising comes to about £100 million a year in the UK. Joining the study were twelve newspaper or magazine groups, at the other end of the pipework. The PwC team tried to match ad impressions the advertisers bought with the ad slots the publishers sold. Negotiating access to data held by intermediaries such as SSPs and DSPs proved complicated – the study ended up taking fifteen months – and difficulties such as differences in data format often made matching impossible.
For the 31 million impressions that the PwC team was able to match end to end, it found that on average only 51 per cent of what the advertisers spent reached the publishers. Two-thirds of the remaining 49 per cent was absorbed by intermediaries’ fees. (On average, 7 per cent of what advertisers spent went to advertising agencies, and a further 8 per cent to DSPs. Supply-side platforms charge their publisher clients a similar amount. Most transactions involve both a DSP and an SSP, and very probably other vendors of data and technical services.) But PwC couldn’t find where almost a third of the 49 per cent – that’s around 15 per cent of advertisers’ spending – had ended up.
It was also one of the first studies to reveal the extent of the data broker industry – how your data was “sent onward” to 3,600+ ad brokers in many cases.
Given all this, it isn’t surprising that publishers in the UK and the U.S. (and elsewhere) have been making concerted efforts to re-engineer the pipework.

Their first big initiative was to make the reader’s device (phone, tablet, laptop or desktop) more central to the process of ad selection. Previously, as soon as a reader accessed a publisher’s webpage, its ad server would immediately be informed that ad slots were about to become available. The ad server is the system that decides which advertisements to show you: it weighs up, for example, the value of the highest bid from the auction against the demands of the publisher’s direct deals.
These days, it isn’t a machine that sits in a publisher’s computer room, but a cloud service, in English-language news publishing almost always provided by Google.
NOTE TO MY READERS: Both UK and U.S. news publishers often worry that advertising revenue they should be getting is instead going to Google. Distrust of Google and resentment of its dominant position are common. But Google also supplies much of the traffic to newspaper websites, and its ad server is integrated deeply into publishers’ systems, which makes moving to a different server difficult. One publisher told me that even though his parent company part-owned one of the handful of other ad server suppliers, shifting to it would have been risky and very disruptive.
Turning your phone into an auctioneer enables news publishers and other websites to reduce their dependence on Google without turning their backs either on Google’s ad server or on the demand for ad slots that flows through Google’s systems. What a publisher does is to add a snippet of computer code to its webpage “headers”; the code instructs your browser, whenever it accesses a page, to send electronic messages to around half a dozen SSPs, inviting them to submit bids for the right to show adverts to you. (The header is the invisible initial part of a webpage which, among other things, tells your browser how to format the page content.)
Only once your browser has received the SSPs’ bids does it alert the ad server, meaning that if Google’s systems are to win the auction they have to improve on the highest bid your browser has been able to obtain. For publishers, another attraction of header bidding is that the SSPs are placed in direct competition with one another: a publisher told me he hoped this would trim what he called the “fat” in SSPs’ fees.
Google, conversely, is not enthusiastic about header bidding, though it has gradually adjusted its systems to accommodate it. The issue is central to an anti-trust lawsuit against Google launched by a consortium of U.S. states with largely Republican attorneys general, who argue that the company “schemed about how to quash header biddin”’. Google rejects the charge. “We do not participate in header bidding … for good reason”, it told the UK Competition and Markets Authority in 2020. Header bidding, it argued, “is characterised by increased latency [electronic delays], reduced transparency and significant user trust and privacy concerns”.
Publishers themselves discovered that the original form of header bidding, in which your device is central to the auction, can have some of the disadvantages that Google cites. The time it takes your browser to establish electronic links to SSPs can cause ads to load slowly, and in the process data is flowing from your phone. In particular, if an SSP has previously deposited a cookie (a small string of letters and numbers that identifies your browser) on your device, it can retrieve that cookie, and so learn something about you. The availability of that information increases the value of the bids your browser receives, but also means that the publisher loses a degree of control over data about its readership.
Increased control is what news publishers often say they want when you ask them about the changes they would like to see in the way their ad slots are auctioned. Many of them think they can gain a greater degree of control through “server-side” header bidding, a different form of the technique whereby bids are gathered from SSPs not by your phone or laptop, but by a computer server designated by the publisher. There is no longer a direct link between the SSPs and your device, which returns to a more passive role. For a publisher wishing to implement header bidding itself, the server-side version of the technique is, however, more complex than its original version. A manager familiar with its challenges tells me that it can require around ten person-years of highly specialist technical work – “pretty heavy lifting for an individual publisher”.
For this reason among others, the UK’s news publishers have set up their own collective AdTech development effort, the Ozone Project. (There is a U.S. equivalent which I will detail in my monograph, but at the Cannes Lions event I had the opportunity to chat with a number of UK publishers). It brings together organisations with quite different political orientations, such as the Guardian, the Telegraph and News UK, publisher of the Times and the Sun. The biggest obstacle to the collaboration, an AdTech specialist who works for right of centre titles told me, was long-standing “emotional attachments … Once you let go of that, and understand that your true competitors are the Facebooks, the Googles, the Amazons … that’s when it becomes easier”. The Ozone Project does the heavy lifting of setting up server-side header bidding, and provides advertisers with a more direct, shorter, less leaky programmatic pipe through which to bid for ad slots.
Leaks from the pipes aren’t the only way in which news sites lose potential advertising revenue. Another is “ad-blocking”, in which a news story or other sort of online material is judged, usually by an automated system, to be unsuitable for advertisers, either in general – because, say, the story reports on distressing events or controversial issues – or for reasons that are specific to the product or service being advertised: no tanning salon wants its ads to appear alongside an article about skin cancer.
NOTE TO MY READERS: Ad-blocking in this context is quite different from the software that users themselves install, which tries to prevent any ads appearing at all.
Newspapers usually arrange their content into broad categories: “news”, “politics”, “sport”, “travel”. Some advertisers simply don’t allow their adverts to be shown alongside “news”. In November last year, for example, the editorial staff of one major U.S. newspaper quite reasonably chose to classify its reporting of COP26 not under “environment” but as “news” or “politics”. As a result, advertising alongside those stories dried up almost completely.
The ad-blocking of “news” is particularly widespread at the moment, I’m told, because of the extensive coverage of the war in Ukraine. While it’s easy to see why advertisers don’t want their ads appearing alongside reports on atrocities, they seem to be underestimating responsible news publishers’ efforts to avoid this. One publisher tells me that in the early weeks of the invasion it entirely removed its homepage masthead ad slot, because of the news content likely to appear beneath it. Another said: “We’re blocking ads ourselves against stories with images of civilian casualties”.
Big advertisers, though, don’t rely on publishers’ own classifications of articles. Because they place ads in a wide range of contexts online, they have learned that it’s wise to employ an AdTech firm that specialises in “verification”. These firms check that ads are displayed for long enough to count as viewable, and that the viewer is actually a human being, not a programmed “bot” that simulates clicks on ads on a website designed to earn money from unwary advertisers. Verification firms now also do the job of trying to stop ads appearing alongside content that advertisers consider unsuitable. A firm’s system will scrutinise the giant flood of ad slots as it flows through the programmatic pipes, and if it judges a slot to be unsuitable, will prevent the DSP that acts on the advertiser’s behalf from bidding for it.
This form of ad-blocking doesn’t always work perfectly, though, so the verification firm’s system will often do another check just before an ad is displayed. (The time this checking takes can be another reason ads are often slow to load.) If the final check suggests a probable violation of brand safety or suitability, and if it’s too late for the publisher’s ad server to find a different ad, the system provides a stock neutral image to fill the slot. One such image, a pattern evoking white clouds against a blue sky, became briefly famous at the start of the pandemic, when it was spotted in the masthead ad slots on the homepages of the New York Times and Wall Street Journal, normally prime real estate for online advertising.
A plausible rough estimate is that UK news publishers lost £50 million in the early months of the pandemic because of ad-blocking of their stories about it (almost $100 million in the U.S). In April 2020 the culture secretary, Oliver Dowden, appealed to advertisers both publicly and privately to relax the blocking. A year later, though, articles were still being ad-blocked even when they were connected to the pandemic only indirectly – a discussion of working from home, say. In the U.S. the Black Lives Matter protests in 2020 also seem to have been the subject of widespread ad-blocking. Vice reports that its coverage in this area attracted less than half the advertising revenue it would have expected.
How does an automated system judge the suitability for advertisements of a news story or anything else on the web? One way, crude but still surprisingly common, is to use a “blocklist”: a list of keywords – several hundred, I’m told, or perhaps even several thousand – associated with content alongside which their ads must not appear. Blocklists are kept confidential, but it seems likely that the ones used in 2020 contained terms such as “coronavirus”, “pandemic”, “lockdown”, etc., etc.
In June 2017, however, the verification provider Integral Ad Science did publish a list of the twenty most commonly blocked terms at the time. First was “explosion”, then “terror”. Others included “dead”, “shooting”, “gun” and “kill”. Domestic terrorism seems to have first prompted the inclusion of these words on blocklists, but today the same words are probably ad-blocking reporting of the war in Ukraine. Publishers also say that a wide range of articles can be penalised accidentally: many things explode, metaphorically at least; footballers shoot; celebrities “dress to kill”. And some of the words that appear on blocklists are surprising. Scott Gatz, of the LGBTQ-oriented U.S. electronic publisher Q.Digital, tells me that one big advertiser entered into a direct deal with it to advertise alongside its Pride coverage, but no ads then appeared on Q.Digital’s websites. He asked to see the blocklist that the advertiser had given to its verification provider – on it were “lesbian”, “gay”, “bisexual”, “transgender” and “queer”.
And (no surprise) “Muslim”, too, seems to be common on blocklists, as is “Trump” and “politics”. And “politics” is also a category to be assiduously avoided.
Inertia may be part of the reason some words linger on blocklists: several people have told me they suspect that the lists are seldom pruned. Certainly, Gatz finds that the staff in an advertiser or advertising agency who design campaigns usually don’t have responsibility for its blocklist and, as in the Pride case, may not even be aware of its contents.
No one I’ve talked to about blocklists really likes them; the verification firms, in particular, urge advertisers to use the more sophisticated services they offer. These involve the wide-ranging use of “crawlers”: programs that systematically digest the content of all the webpages on which their clients are likely to bid for ad slots, sometimes also analysing the links from those pages to other sites. The firms’ systems use artificial intelligence techniques to classify all this web content, “reading … the adjectives as well as the nouns”, as Richard Reeves of the Association of Online Publishers puts it. Crawling ranges far beyond news websites, but these sites are updated continuously, so are crawled intensively: one publisher estimates that every new addition to his paper’s site will be crawled and assessed for brand safety and suitability within fifteen minutes to an hour.
All of this technology and these techniques have had a considerable influence on the flow of advertising money. While many regard it as better than the mechanical use of blocklists, publishers aren’t always happy with the results. Gatz, for example, says that Q.Digital’s webpages are often classed as “adult”, a category that includes sexually explicit material and is often avoided by advertisers. Nor have AI-based techniques entirely displaced blocklists. An executive at one advertising agency warns that you can “lose a client” by inadvertently advertising alongside content the client regards as unsuitable. A manager at another agency says that she personally is prepared to advertise without a blocklist, but understands why others won’t: ‘It’s so hard from having so many safety nets to going, we are just going to remove this … It’s like bungee jumping and going, we are going to remove the net below you.’

If, however, you are trying to identify the single most significant cause of journalism’s current economic difficulties, as I have covered ad naueum, its the third-party cookie. And despite all the press, cookies ain’t going away for awhile.
Refresher: a third-party tracking “cookie” is placed on a website by someone other than the owner (a third party) and collects user data for the third party. As with standard cookies, third-party cookies are placed so that a site can remember something about the user at a later time. It is operated perhaps by a supply-side or demand-side platform. As Thomas Beauvisage and Kevin Mellet have pointed out in what I think is the definitive short-form text on the subject for most readers, these cookies form an infrastructure that permits an individual – or their browser at least – to be identified in multiple online contexts and by multiple organisations. (There are giant matching tables that can, for example, translate the cookie by which you are known to an SSP into the cookie used by a DSP.) Why advertise to a user through an expensive direct deal with a high-quality news website when you can reach them with the same ad more cheaply on other sites they visit, ones that rarely change or have content that can be produced without paying professional journalists?
Yes, third-party cookies are slooooowly on the way out. Originally set to end this year, and then by late 2023, and now “sometime in 2024”. All major browsers have said they will block them by default. But, of course, users can still be identified in other ways, but no framework for doing this has been adopted sufficiently widely to form an equivalent infrastructure, and regulators have been playing around with various methods to ensure that such an infrastructure doesn’t come about. In November 2021, Elizabeth Denham, then the UK’s information commissioner, warned that her office, which has long-standing concerns about the sharing of user data in ad auctions, “will not accept proposals based on underlying AdTech concepts that replicate or seek to maintain the status quo”. And then issued … well, issued no ideas on how to accomplish this.
There is therefore a revival of interest in “contextual targeting”: advertising focused not on the identity of the user but on the content with which the user is interacting at any given moment. News websites, with their rich, diverse and ever-changing content, fit the bill nicely. That’s grounds for a little optimism, for no one has a deeper and more up to date understanding of the content of a news website than its publisher. A verification firm, though, with its active crawlers and AI-based analytical tools, may hope to come a close second, and several such firms have now added contextual targeting to the services they offer advertisers. In fact, I foresee a huge “contextual targeting advertising” industry arising.
But the publishers I have spoken to believe it is they, not AdTech firms, who should be giving advertisers the information they need for effective contextual targeting. One publisher even speculated about denying access to AdTech’s crawlers. Said one:
“If you’re a London Times, Telegraph or an FT, or a New York Times you can probably do that. But if you’re a smaller player, it is going to be damn near impossible. So you’ll crawl back to Google for help. And their power will just grow stronger and stronger. Thanks GDPR”.
If a news site is, as he put it, a “mass-market proposition”, then it will of necessity depend on open auctions, and advertisers need the reassurance of the automated assessment of brand-safety risks.
There is a growing sense among advertising practitioners that they need to take responsibility not just for the content of adverts, or even for brand safety as narrowly conceived, but for the wider impact of ad spending. This means not only making sure you aren’t funding hate speech or misinformation, even inadvertently, but also not relying on the mechanical use of blocklists. Which is why there is huge concern over blocklists that include words related to climate change.
So … if you’re a big advertiser, to advertise “consciously” almost certainly means being more selective. On average, the firms that took part in the PwC study each advertised, in just three months, on more than forty thousand websites in the UK alone. That’s advertising on a scale that defies genuine human oversight. “Conscious” ad spending must surely involve supporting activities that contribute to human betterment. Much of what we know about the world we have to learn from others, including journalists, who must draw on their experience to distinguish unfounded, attention-seeking speculation from frequently mundane facts, and exercise the courage to pursue the truth even when it is awkward, discomfiting and dangerous to do so. Intermediaries’ excessive fees damage the economic base of this crucially important activity, just as indiscriminate ad-blocking of ‘news’ disincentivises its production.
It is encouraging that the Guardian’s subscribers and “supporters” (who make regular donations) now number more than a million. The Financial Times also has more than a million digital subscribers and the New York Times more than ten million.
But a handful of successful titles isn’t enough. Local and regional newspapers can still make a big contribution to their communities – local, not just national, decision-makers must be held to account – but have suffered especially severely from declines in circulation and advertising revenues. And then there are outlets that specialise in reaching the very audiences whose sexual orientation, or ethnic, religious or gender identity are associated with words that too often populate blocklists. Such outlets are worth supporting in themselves, of course, but they also offer a way for advertisers to broaden their reach. In the end, however, advertising revenue alone will seldom be enough to support extensive in-depth journalism.
That will require diverse sources of income, above all from sales and subscriptions, but also from membership schemes, events, philanthropy and in some cases – local journalism included – even central government support. And that gets me to my other work-in-progress on the journalism industry. But not today.
The above piece is from my series ….
