A British artificial intelligence company has shown that it can compute the shapes that proteins fold into, solving a 50-year problem in biology. But for most of my readers the real name-of-the-game when we talk AI is natural language processing.
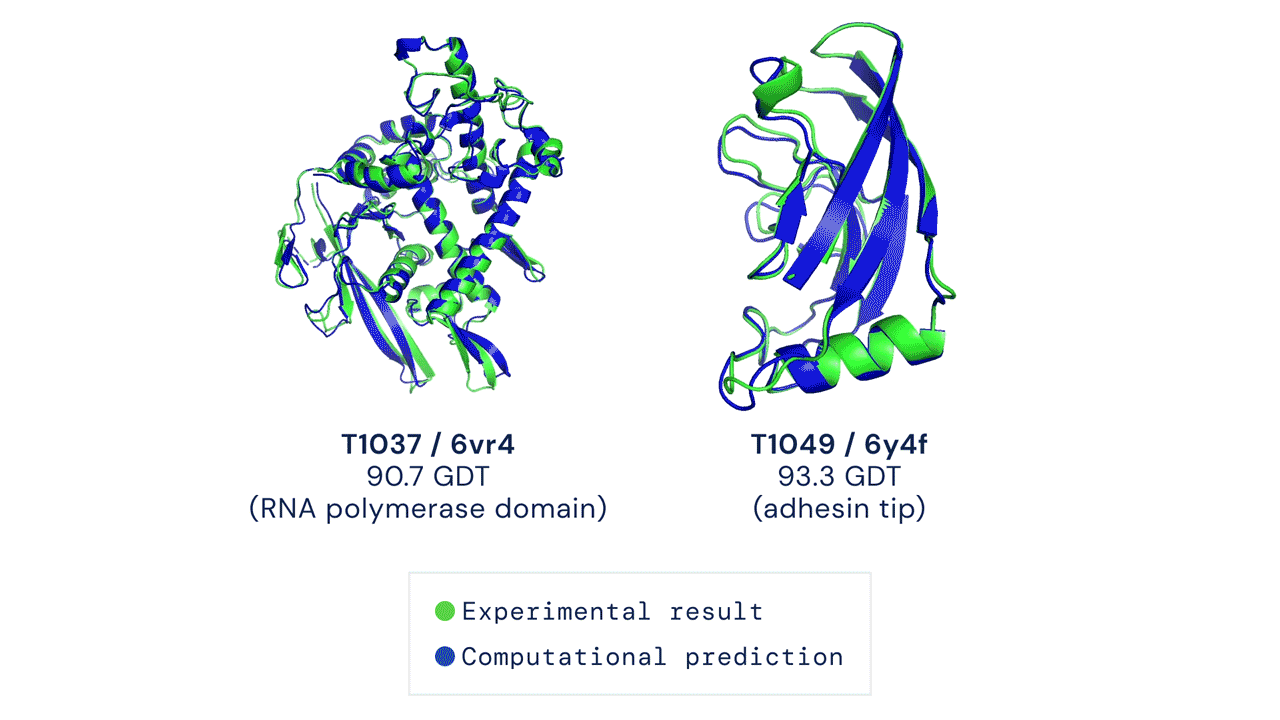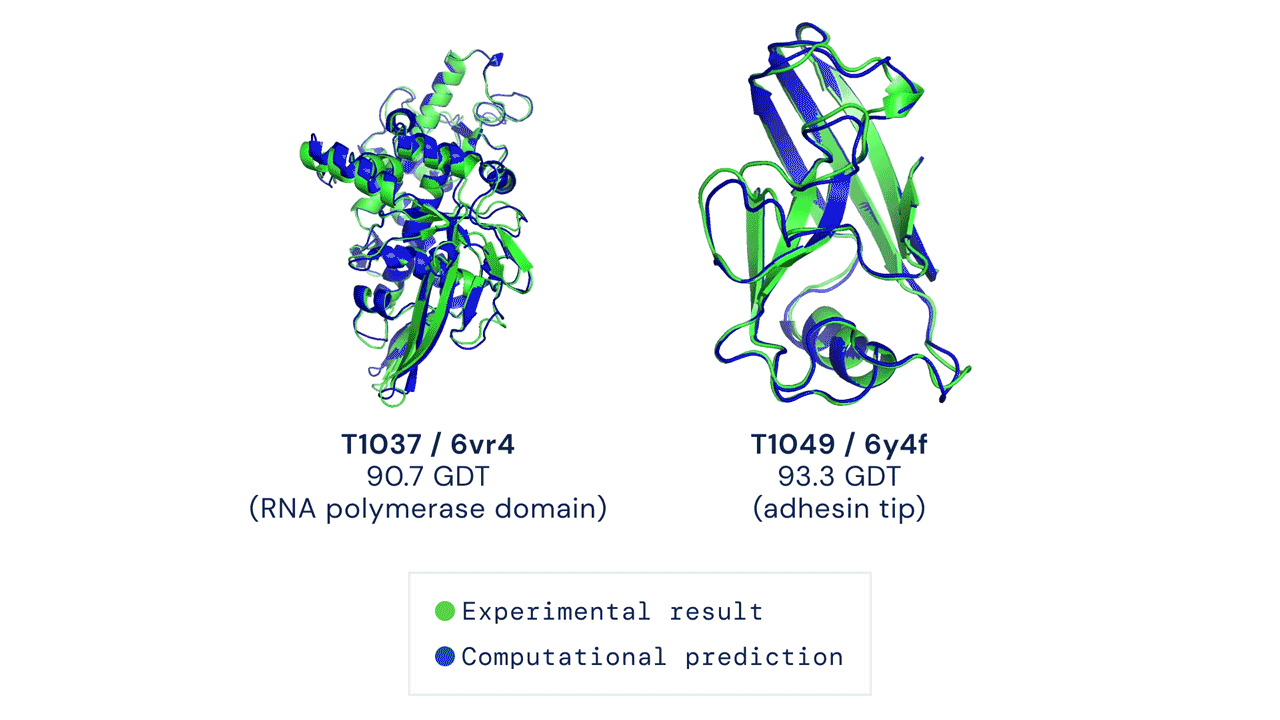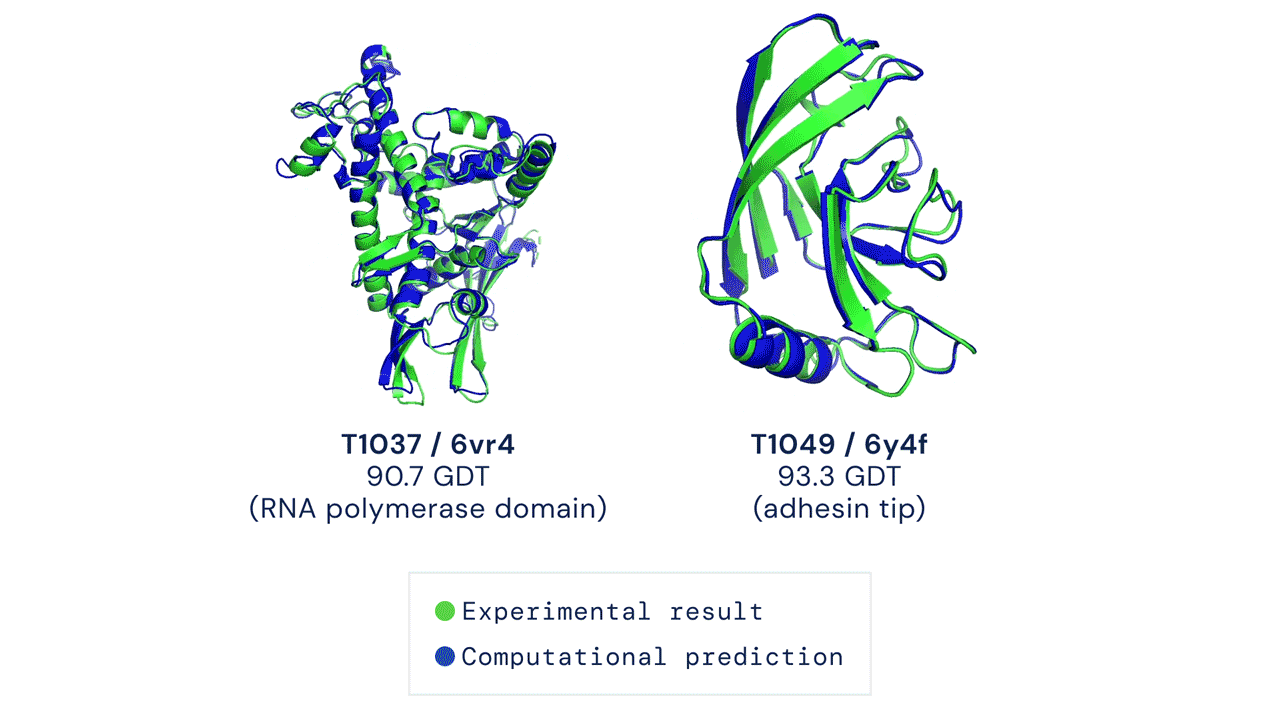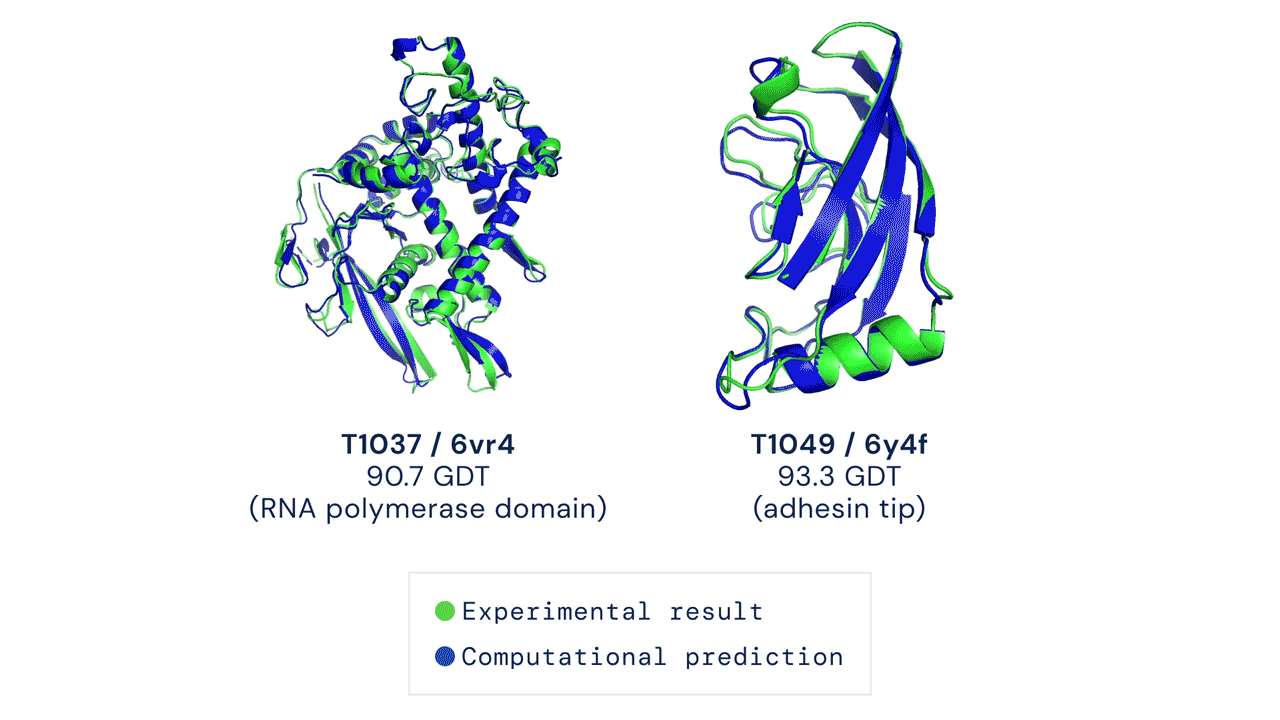
ABOVE: Two examples of protein targets in the free modelling category. AlphaFold predicts highly accurate structures measured against experimental result.
BELOW: AlphaFold is a once in a generation advance, predicting protein structures with incredible speed and precision. This leap forward … from AlphaFold to AlphaFold 2 … demonstrates how computational methods are poised to transform research in biology and hold much promise for accelerating the drug discovery process.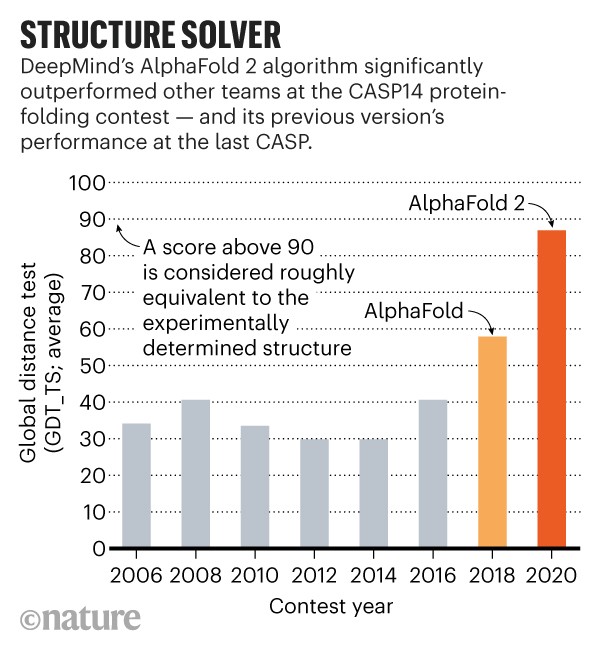
3 December 2020 (Chania, Crete) – As the story is told, it was a cold March day in 2016 and DeepMind CEO Demis Hassabis reportedly told computer scientist David Silver: “I’m telling you, we can solve protein folding.” Four years later, the London-based AI lab says they’ve figured out the protein-folding problem – a biological mystery that’s flummoxed scientists for 50 years.
On Monday, DeepMind announced a breakthrough in the area of protein folding, which uses a protein’s DNA sequence to predict its three-dimensional structure. With this new ability, we can better understand the building blocks of cells and enable advanced drug discovery. This is a huge scientific and industrial milestone. As Dr. Chris Donegan told me “this is a problem that has consumed computational biologists for decades. It is a real inflection point”.
As I noted in a long post last night to my science listserv, it’s really hard to overstate the importance of this, though it will take years to become apparent. It’s rather like how the sequencing of the human genome in the late 1990s led to us being able to produce an mRNA vaccine to fight COVID-19 in just two days, given its sequence (yes, it took a total of 10 months but all the rest of the time was spent on production and trials).
The complexity of protein folding is mindblowing: it depends on interactions between existing parts of the protein as it’s produced, which then are influenced by subsequent parts. For those of us that have had the time to aim our complexity lens on the COVID-19 pandemic, it’s all even more astonishing. And thrilling. Between 2018 and 2020, Alphafold has gone from impressive to superhuman – and proving that machine learning approaches can solve the folding problem.
NOTE: for a short history of DeepMind click here.
What DeepMind did, in a nutshell
I have followed DeepMind for almost 5 years. I got hooked in 2016 when I was in Zurich, Switzerland with my fellow artificial intelligence students. We got up early to watch the live feed from Korea as Lee Se-dol, a South Korean professional Go player, and AlphaGo, a computer program developed by DeepMind, played the board game Go. As we all know, Lee got trashed. I was fascinated. I even learned to play (rudimentary) Go. One of my AI professors made an introduction for me at DeepMind and I was off to do a deep dive into their work. It’s been a Master Class in pattern-matching, brute-force search and neural networks. It’s been technically sweet, and now looks to have cosmic significance.
My second degree at university was physics but over the last 20 years my primary science reading has been biology (I lost both parents to debilitating, long-term diseases) so I have a pretty good understanding of what DeepMind accomplished.
To keep it simple, mitochondria may be *the powerhouse of the cell* but proteins are one of its main building blocks. So where does protein folding come in? Whichever shape a protein folds into will decide its function. The challenge is that proteins can take a virtually infinite number of forms. Bottom line: if you can predict a protein’s shape, then you can essentially predict its function. Since research suggests many diseases – Alzheimer’s, Parkinson’s, diabetes, cancer – are influenced by incorrect protein folding, this breakthrough is a very big deal for disease research and drug discovery.
Two years ago, the company released its first attempted protein-folding solution. But it wasn’t quite effective enough for use in the field. John Jumper, the protein-folding team’s senior researcher, said at the time:
“We used relatively off-the-shelf neural network technology [V1]. When the team tried to build on that version, they hit a real wall in what they were able to do.”
So this time, the team custom-built a neural network from the ground up. Unlike V1, which was made of separate components, the new AlphaFold is an end-to-end system – which can translate to more accurate results. The flip side: like most end-to-end systems, AlphaFold’s decision-making is opaque and hard to explain. While DeepMind can’t offer full insight into how the model arrived at a prediction, it will provide scientists with a confidence measure for each prediction. And a very detailed paper will be submitted for peer review.
Yes, the critics have circled. Some critics say that due to lack of precision, it’s “laughable” to call the problem solved. Others will likely remain skeptical until they can examine AlphaFold’s code, calling on DeepMind to release it to the public domain. And virtually all plan to wait and see how the model performs IRL. For those of you who want more, the DeepMind briefing note is well worth your time. Just click here.
For biology buffs: Can’t get enough of protein folding? DeepMind created an illustrated video animation explaining how the process works:
THE BIG PICTURE: caveats aside, all the experts I spoke with agree this is a major step forward in disease research and drug discovery. This could be an “Imagenet moment” that will trigger a wave of investment and innovation. That “moment” refers to Alex Krishevsky. Back in 2011, computer vision was stuck in the doldrums, not really good enough to generalise and be present everywhere. Then in 2012, Alex Krishevsky, Ilya Sutskever, and Geoffrey Hinton used a deep neural network … commonly referred to as “AlexNet” … to make a huge improvement to computer vision performance. This triggered not just a boom in computer vision but a wave of venture and corporate investment in machine learning more widely. I’d expect AlphaFold 2 to do the same.
But for most of my readers, the most important aspect of AI is its impact on language. And it was “AlexNet” which I noted above that set the pace for artificial intelligence improvement in Natural Language Processing (NLP). Krishevsky set a new benchmark for machine vision and as a consequence of that technical breakthrough researchers realized that for two specific types of tasks … machine vision and text/speech recognition … neural networks would get us to “good enough performance” and then even more. It industrialised written language, speech and image recognition. The last few years … and most certainly the next few years … will be all about NPL. The following are my thoughts on how this might all play out.

Ah, it’s true. First we shape our tools and then they shape us. So let’s lead off with a report from the “AI and Financial Reporting News Department”.
Companies have long seen annual reports and other corporate disclosures as opportunities to portray their business health in a positive light. Increasingly, the audience for these disclosures is not just humans, but also machine readers that process the information as an input to investment recommendations. AI researchers have found that companies expecting higher levels of machine readership prepare their disclosures in ways that are more readable by this audience.
It’s called “machine readability” and it is measured in terms of how easily the information can be processed and parsed, with a one standard deviation increase in expected machine downloads corresponding to a 0.24 standard deviation increase in machine readability. For example, a table in a disclosure document might receive a low readability score because its formatting makes it difficult for a machine to recognize it as a table. A table in a disclosure document would receive a high readability score if it made effective use of tagging so that a machine could easily identify and analyze the content.
To gauge the extent of a company’s expected machine readership, researchers are using a proxy: the number of machine downloads of the company’s filings from the US Securities and Exchange Commission’s electronic retrieval system. And what they are finding is companies are going beyond machine readability and are managing the sentiment and tone of their disclosures to induce algorithmic readers to draw more favorable conclusions about the content. For example, companies avoid words that are listed as negative in the directions given to algorithms.
There are a number of research papers out there that show the work being done but one of the best I have seen just popped up in my NBER Working Paper feed titled How to Talk When a Machine Is Listening: Corporate Disclosure in the Age of AI and it explores many of the implications of this trend. Rather than focusing on how investors and researchers apply machine learning to extract information, this study examines how companies adjust their language and reporting in order to achieve maximum impact with algorithms that are processing corporate disclosures. I have a NBER subscription but last I checked you should be able to access that article for free. If not, email me (address at the end of this post) and I can send you a PDF.
Yes, indeed. First we shape our tools and then they shape us.
That boom in machine vision capabilities I noted above triggered an AI wave of startup formation, venture capital investment, corporate spending and newspaper headlines:
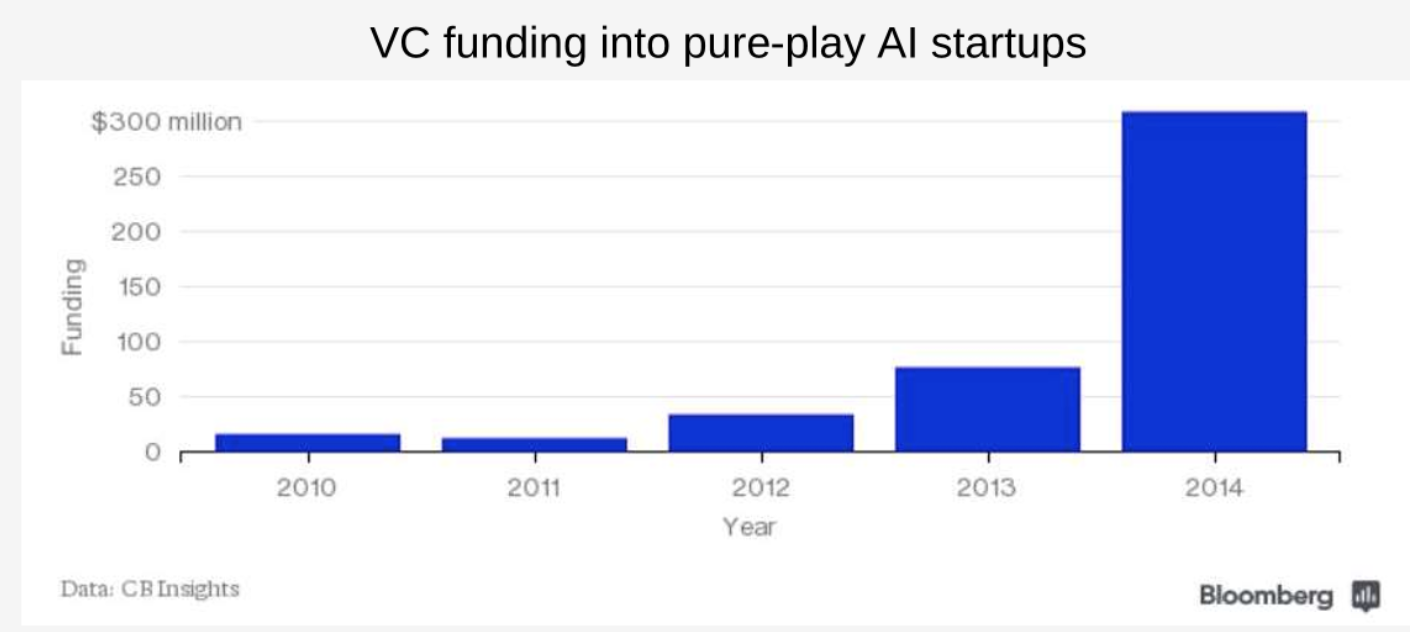
This technical trigger sat on a set of infrastructure that enabled it to spark, but also to spread. These depended on Moore’s Law and the declining price of computation leading to:
• many people using many computers, and creating lots of digital data (such as speech recordings or pictures) that could be used as training data
• super-cheap compute cycles to run more complex neural nets on them
• a vast digital infrastructure of connected devices and services on which small (or large) breakthrough applications could be rapidly delivered to huge markets of consumers or businesses
• the declining cost of software entrepreneurship, enabling a couple of metaphorical kids in a garage to cheaply hack something together and see if it stuck.
And so today in 2020, we think nothing of high-quality computational manipulation of images. We open our phones with our faces. We track visitors with our cheap consumer webcams. I have a free app that recognizes any plant I point my phone at. Capabilities that were not available anywhere in the world a decade ago are now too cheap to meter. Autonomous vehicles are dependent on these breakthroughs to navigate the roads.
So it is no surprise that the field undergoing a rapid ascendance is natural NLP, built on deep neural networks. Natural language processing allows software to make some sense of the written word. By “make sense of,” I don’t mean understand. I mean work its way through enough of the complexity to produce things that look acceptable to a human. And Transformers took things to a new level, released initially by Google in 2017. It was quickly followed up by BERT and then OpenAI’s GPT-2 during 2019, followed by GPT-3 this year.
NOTE: the GPT-3 story needs a separate post. I think took much has been written about the system being “imperfect” when we know it will change Two years ago – only two years ago! – be laughed at the primitive nature of deep fakes. Look at the astonishing speed with which it has improved.
GPT-3 will be applied to more and more varied tasks than anyone predicted, and also change at astonishing speed. When OpenAI released GPT-3 this past July, it marked the first time a general-purpose AI saw the light of the day. Over the summer I produced a long-read overview of the history of knowledge technologies that preceded GPT-3 and I had noted that creating a generalizable tool for actually answering the question you wanted answering was hard. People believed it required lots of knowledge about the world to be explicitly encoded in specific ways. The Cyc project (now Cycorp) tackled this area for 30 years before launching commercially.
What GPT-3 has achieved is to encapsulate knowledge, billions of words of it, in a sufficiently parameterized model that it can give granular answers to very different types of queries, across multiple domains. But we need to take the really long view on tech. Just as recent developments in augmented reality has shown us that looking at screens and pecking at keyboards will surely seem quaint by 2030, GPT-3 and its developing derivatives will enable our ability to mine and augment our collective intelligence. There is so much I need to write about this but I’ll save it for 2021.
I have discussed many of these NPL technologies extensively in the past. One key insight is the use of pre-trained models and the concept of attention which allows words to be analysed in a much broader context, perhaps whole paragraphs, than previous approaches in NLP. If you study the field you’ll see that natural language processing is following a similar path to machine vision, so we are seeing rapid improvements in applications that use text. Google had already implemented BERT into its pride-and-joy, the search engine – adding capabilities for “understanding” never possible before:
By applying BERT models to both ranking and featured snippets in Search, we’re able to do a much better job helping you find useful information […] Particularly for longer, more conversational queries, or searches where prepositions like “for” and “to” matter a lot to the meaning, Search will be able to understand the context of the words in your query.
I am starting to see increasing venture investments in the sector. Synthesize is one such firm I will write about next year which raised $85 million in venture capital, bundling many such pre-trained language models and tools for developers to apply in legaltech and legal analytics applications.
Oh, and here is something I created using GPT-3:
Natural language processing will be the next breakthrough in artificial intelligence.
It will vastly reduce the number of human tasks humans must perform, and use the computer’s computing power to automate their human functions.
For decades, all the relevant research on natural language processing was done on the development of syntactic parsing — figuring out which words fit a specific grammatical structure.
Now we have the power to do a much deeper job and tackle the serious cognitive problems of understanding and reasoning in language.
The programs don’t look like their human counterparts and we don’t always know whether their uses are on purpose or incidentally.
Not bad, is it?

Transformers are already becoming commonplace. Microsoft, Google, Alibaba and Facebook have invested buckets of cash in these tools and make them widely available. But so too is the Chinese insurer, PingAn, whose framework Omni-Sinitic is at the top of many leaderboards.
Where could NLP take us? There are obvious places where better understanding of and generation of text can be useful, including chat systems for customer services, enhanced writing aids (autofill for text), monitoring news feeds for financial services, fraud, market intelligence and more.
NOTE: this is why Facebook’s recent acquisition of customer service and chatbot startup Kustomer is so big. It not only helps FB continue its push into online shopping, but it also demonstrates the acceleration of automation and chatbots growing role in ensuring companies can train their staff to manage and deal with customers over data laws, a point raised this past Monday in the chatbot/ediscovery webinar many of my readers attended.
But there are also places it will go that we didn’t imagine. Several papers on MedXriv have shown that researchers found, through text analysis of 8.2 million clinical notes from 14,967 patients subjected to COVID-19 PCR diagnostic testing, that AI text analysis was predictive of Covid-positive test. Furthermore, they found some conditions to be more predictive than others.
To my science chums: as noted last week during the Johns Hopkins Zoom chat on COVID and NLP, understanding the temporal dynamics of COVID-19 patient phenotypes is necessary to derive fine-grained resolution of the pathophysiology. These researchers are using state-of-the-art deep neural networks over an institution-wide machine intelligence platform.
More importantly, the application of Transformers to mathematical reasoning shows better NLP creates better tools for humans to manipulate and understand information. AlexNet really triggered a cavalcade of investment. Cheap CCTV cameras can tell the difference between a person and a fox. Neobanks can take you through know-your-customer processes with a selfie and a photo of a passport. Cars can, roughly, navigate streets.
Bottom line? The domain of textual and conversational analyses, deeper context, and better semantics will all be next, with a slew of new applications built on top.
BUT, baby steps …

The more I studied (well, still study) AI and neuroscience, the more I saw the incontrovertible evidence that the human brain has capabilities that are, in some respects, far superior to those of all other known objects in the cosmos. As I have noted in previous posts, it is the only kind of object capable of understanding that the cosmos is even there, or why there are infinitely many prime numbers, or that apples fall because of the curvature of space-time, or that obeying its own inborn instincts can be morally wrong, or that it itself exists.
Nor are its unique abilities confined to such cerebral matters. The cold, physical fact is that it is the only kind of object that can propel itself into space and back without harm, or predict and prevent a meteor strike on itself, or cool objects to a billionth of a degree above absolute zero, or detect others of its kind across galactic distances.
But still …. no brain on Earth is yet even close to knowing what brains do in order to achieve any of that functionality. That is the wonder. I also believe that since not all of the properties of nature are mathematically expressible – why should they be? it takes a very special sort of property to be so expressible – that there are aspects of our nature that we will never get to by way of our science. An outright materialist could argue that all my acts, from the day of my birth, have been a determined result of genetics and environment. No. Not all of my acts are determined at the molecular and submolecular level.
Paul Kay, my biology professor at Cambridge, posited that intuition comes to be learned, much as we learn about right and wrong, good and evil, in much the same way that we learn about geometry and mathematics. It is cultural learning, and it does not arise from innate principles that have evolved through natural selection. It is not like the development of language or sexual preference or taste in food.
I like that. We know that gut-feelings, such as reactions of empathy or disgust, have a major influence on how children and adults reason about morality. I like it because it allows for moral realism. It allows for the existence of moral truths that people come to discover, just as we come to discover truths of mathematics. That “intuition” is not a mere accident of biology or culture.
Yes, you can teach a machine to track an algorithm and to perform a sequence of operations which follow logically from each other. It can do so faster and more accurately than any human. Given well defined basic postulates or axioms, pure logic is the strong suit of the thinking machine.
But exercising common sense in making decisions and being able to ask meaningful questions are, so far, the prerogative of humans. Merging intuition, emotion, empathy, experience and cultural background, and using all of these to ask a relevant question and to draw conclusions by combining seemingly unrelated facts and principles, are trademarks of human thinking, not yet shared by machines. Even as we prepare the machine learning algorithms and try to mimic the brain with deep neural networks in all domain sciences, we remain puzzled on the mode of connected knowledge and intuition, imaginary and organic reasoning tools that the mind possesses.
I’ll leave the last word to Maria Spiropulu, my physics professor at ETH Zurich, who explains it this way:
“It is difficult, perhaps impossible, to replicate on a machine. GPT-3 and other NLP technologies remain very interesting. But infinite unconnected clusters of knowledge will remain sadly useless and dumb. When a machine starts remembering a fact (on its own time and initiative, spontaneous and untriggered) and when it produces and uses an idea not because it was in the algorithm of the human that programmed it but because it connected to other facts and ideas – beyond its “training” samples or its “utility function” – I will start becoming hopeful that humans can manufacture a totally new branch of artificial species – self-sustainable and with independent thinking – in the course of their evolution.”
* * * * * * * * * * * * * * *

Palaiochora, Crete 730 01
Greece
To contact me just email : [email protected]