
Algorithms trained on biased data sets often recognize only the left-hand image as a bride
27 July 2018 (Serifos, Greece) — As we have all come to learn, artificial intelligence (AI) systems are only as good as the data we put into them. Bad data can contain implicit racial, gender, or ideological biases. Many AI systems will continue to be trained using bad data, making this an ongoing problem. Many seem to believe that bias can be “tamed” and that the AI systems that will tackle bias will be the most successful. But as my AI program at ETH Zurich (the science, technology, engineering and mathematics university in the city of Zürich, Switzerland) winds down this year our conversations on the matter … whenever someone comes up with a “taming bias” idea … seem to be dominated by an “as if!” response from my comrades. But I am not “all cynical” on this. Read on.
Two major stories hit the grid this week that caused me to think more about bias, plus the real problem with machine learning:
- At the Google Cloud Summit this week (my CTO, Eric De Grasse, was attending), Diane Greene (Google’s director of cloud computing) noted that facial recognition technology does not yet have the diversity it needs because it has “inherent biases”. Her remarks were predicated by the study released this week showing that Amazon facial recognition software wrongly identified 28 members of Congress, disproportionately people of color, as police suspects in a criminal database.
- IBM had to fess up that internal company documents showed that medical experts working with the company’s Watson supercomputer found “multiple examples of unsafe and incorrect cancer treatment recommendations” when using the software which showed there were serious questions about the process for building content and the underlying machine learning technology
This second story is more serious and I will address it in the second part of this post which I will publish tomorrow. But first … let’s talk about bias.
Oh, that skewed data!
When Google Translate converts news articles written in Spanish into English, phrases referring to women often become “he said” or “he wrote”. Software designed to warn people using Nikon cameras when the person they are photographing seems to be blinking tends to interpret Asians as always blinking. Word embedding (also known as word vectors), popular algorithms used to process and analyse large amounts of natural-language data, characterize European American names as pleasant and African American ones as unpleasant.
These are just a few of the many examples we discussed in my AI program, AI applications systematically discriminating against specific populations. Biased decision-making is hardly unique to AI, but as many researchers have noted, the growing scope of AI makes it particularly important to address. Indeed, the ubiquitous nature of the problem means that we need systematic solutions. Here I want to discuss some basics, plus a few strategies discussed in my program.
In both academia and industry, computer scientists tend to receive kudos (from publications to media coverage) for training ever more sophisticated algorithms. But relatively little attention is paid to how data are collected, processed and organized. A major driver of bias in AI is the training data. Most machine-learning tasks are trained on large, annotated data sets. Deep neural networks for image classification, for instance, are often trained on ImageNet, a set of more than 14 million labelled images.
Note: obviously the amount of data you need depends both on the complexity of your problem and on the complexity of your chosen algorithm. But with images, size really does matter. It explains why last year one image software program experienced an epic fail in an e-discovery review project which I will explain in part 2.
In natural-language processing, standard algorithms are trained on corpora consisting of billions of words. Researchers typically construct such data sets by scraping websites, such as Google Images and Google News, using specific query terms, or by aggregating easy-to-access information from sources such as Wikipedia. These data sets are then annotated, often by graduate students or through crowdsourcing platforms such as Amazon Mechanical Turk. During my AI program we did this multiple times. But such methods can unintentionally produce data that encode gender, ethnic and cultural biases.
Why? Frequently, some groups are over-represented and others are under-represented. For instance, more than 45% of ImageNet data, which fuels research in computer vision, comes from the United States, home to only 4% of the world’s population. By contrast, China and India together contribute just 3% of ImageNet data, even though these countries represent 36% of the world’s population. This lack of geodiversity partly explains why computer vision algorithms label a photograph of a traditional U.S. bride dressed in white as “bride”, “dress”, “woman”, “wedding” … but a photograph of a North Indian bride gets tagged as “performance art” and “costume”.
In medicine, machine-learning predictors can be particularly vulnerable to biased training sets, because medical data are especially costly to produce and label. Last year, researchers used deep learning to identify skin cancer from photographs. They trained their model on a data set of 129,450 images, 60% of which were scraped from Google Images. But fewer than 5% of these images are of dark-skinned individuals, and the algorithm wasn’t tested on dark-skinned people. Thus the performance of the classifier could vary substantially across different populations.
But, hey … let’s blame the algorithm!
Another source of bias can be traced to the algorithms themselves. A typical machine-learning program will try to maximize overall prediction accuracy for the training data. If a specific group of individuals appears more frequently than others in the training data, the program will optimize for those individuals because this boosts overall accuracy. Computer scientists evaluate algorithms on “test” data sets, but usually these are random sub-samples of the original training set and so are likely to contain the same biases.
And so … SURPRISE! … flawed algorithms can amplify biases through feedback loops. Consider the case of statistically trained systems such as Google Translate defaulting to the masculine pronoun. This patterning is driven by the ratio of masculine pronouns to feminine pronouns in English corpora being 2:1. Worse, each time a translation program defaults to “he said”, it increases the relative frequency of the masculine pronoun on the web – potentially reversing hard-won advances towards equity. The ratio of masculine to feminine pronouns has fallen from 4:1 in the 1960s, thanks to large-scale social transformations.
Tipping the balance
Biases in the data often reflect deep and hidden imbalances in institutional infrastructures and social power relations. Wikipedia, for example, seems like a rich and diverse data source. But fewer than 18% of the site’s biographical entries are on women. Articles about women link to articles about men more often than vice versa, which makes men more visible to search engines. They also include more mentions of romantic partners and family. Thus, technical care and social awareness must be brought to the building of data sets for training. Specifically, steps should be taken to ensure that such data sets are diverse and do not under represent particular groups. This means going beyond convenient classifications – “woman/man”, “black/white”, and so on — which fail to capture the complexities of gender and ethnic identities.
Now, despite my initial cynicism above, some researchers are already starting to work on this (for a good summary read this recent article from Nature). For instance, computer scientists recently revealed that commercial facial recognition systems misclassify gender much more often when presented with darker-skinned women compared with lighter-skinned men, with an error rate of 35% versus 0.8%. To address this, the researchers curated a new image data set composed of 1,270 individuals, balanced in gender and ethnicity. Retraining and fine-tuning existing face-classification algorithms using these data should improve their accuracy.
To help identify sources of bias, I began looking at annotators that systematically label the content of training data sets with standardized metadata. Several research groups are already designing “datasheets” that contain metadata and “nutrition labels” for machine-learning data sets. For just one example, I direct you to a program at MIT (click here).
CONCLUSION
Obviously, every training data set should be accompanied by information on how the data were collected and annotated. If data contain information about people, then summary statistics on the geography, gender, ethnicity and other demographic information should be provided. For instance, for a very long time Nature magazine has done its homework and published its data graphs like this:
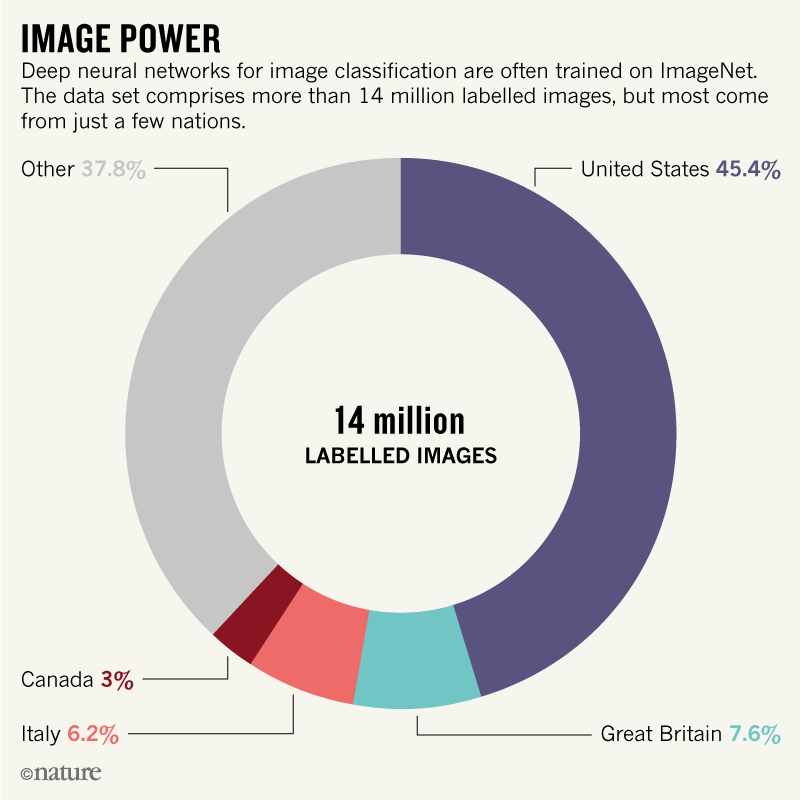
If the data labelling is done through crowdsourcing, then basic information about the crowd participants should be included, alongside the exact request or instruction that they were given.
Next up …
The areas where machine learning is trying to be good requires enormous amounts of data and quantitative comparisons (is that an apple or a face? can I make a medical prognosis?). But show it something it has never seen before and it won’t have a clue. Best example: if you train an ML to play “Go” on a 19 x 19 board, and then add an extra row and column, it won’t be able to extrapolate how to play. Humans beat it hands down. In some cases, it cannot even determine a move.
ML: it’s a brittle system. And none of the enormous optimism I read about ML from folks like Erik Brynjolfsson and the like applies to rare problems, with little data, and novel situations. Which is most of life actually. I’ll talk about this in part 2.