

30 November 2017 (Helsinki, Finland) – I end my conference year in Helsinki, Finland for the Slush conference/trade show/workshop. Briefly:
- Despite the sub-zero temperatures, more than 20,000 people come to Helsinki for the annual Slush event which matches startups with investors. Bigger than almost any other event, the 2,300+ startups came from around the world to match-make with 1,100+ investors, plus attendees that just want to see the next “new new thing”. There are scores of workshops, tutorials, etc.
- It is held at the Messukeskus Convention Centre (“that cool cyberpunk gothic-tech building” as noted by my companion and media staffer, Angela Gambetta). It is always wall-to-wall with applications that range from AI applied text analytics/text extraction to augmented reality to chat bots to food to robotics. I think after all the hoopla surrounding Brexit and Trump it is an affirmation that technology and innovation is thriving in a country that gave birth to Linux (still the most influential operating system in the world) and Nokia. Oh, and they developed Angry Birds. Oh, and Clash of the Clans, too.
As I have written before, European technology (and more generally, technology outside of the U.S.) has now broken the mould of trying to be the next “Silicon Valley” and created its own identity and momentum. U.S. companies … Apple, Cisco, Facebook, Google, IBM, Microsoft, etc., etc. … are always here in force to recruit talent because as one U.S. tech recruiter told me:
“there are something like 4.8 million professional developers in Europe compared to 4.1 million in the U.S. Given Trump’s threats to curtail work visas, we need to be here looking for talent for our research and development centers.”
As I have noted before, in the last two years U.S. companies have opened more new R&D centers in Europe than in the U.S. or anywhere else in the world.
I promise not to bomb your Inbox while I am here but one session today addressed AI bias and fairness … a topic that seems to be on everybody’s tech list. And there will be several other chat times about AI and bias later at Slush.
This morning’s session intrigued me alone almost purely for one of the graphics a presenter used:
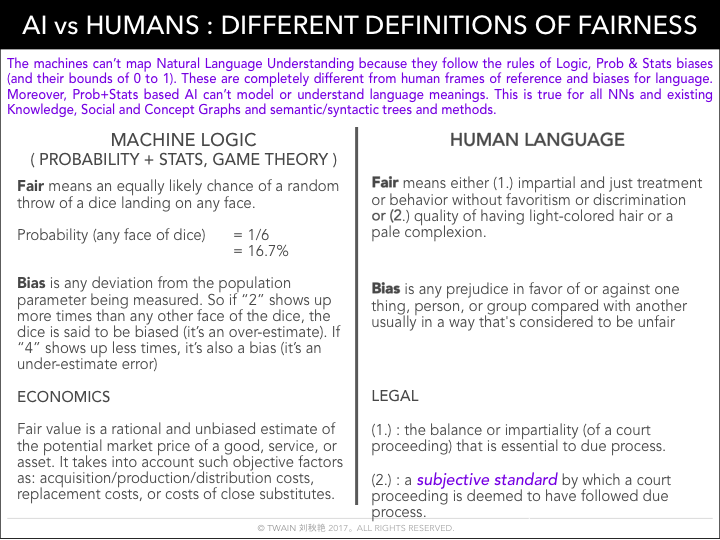
Her points were specific and direct. We recorded the session so let me just note what I think were the highlights:
- We’ve been under misassumptions that the machines are “objective,” “fair” and “unbiased” because of implementations of Aristotelian, Cartesian and Leibniz’s logic as well as Bayesian probability of event occurrences and Galton-Fisher-Pearson statistics for modeling the deviation of individual event occurrences from the mean of observed events — which were all designed to remove human “irrationality” from reasoning processes.
- We’ve followed all their rules for data capture, classifications {false = 0, true = 1, % of a piece of information being true or false or statistically significant} to make the data sets and the machine algorithms as conformant to their logic and the removal of human variables and variances as possible. So that there’d be a universal mathematical language logic and the removal of human biases.
- So WHY are the leading AI researchers, Google’s SVP of Search, Managing Directors at BCG and others talking about “BIAS IS THE BIGGEST THREAT TO AI DEVELOPMENT” and how data biases caused the 2008 financial crisis?
- Well … because the way fairness and bias are defined in mathematical logic is NOT the same as how we define and mean it in human language, across cultures and across disciplines. That’s why we need new paradigms & tools.
She set out three examples which I will expand upon below:
1. Scientists at the Department of Computer and Information Science at the University of Pennsylvania conducted research on how to encode classical legal and philosophical definitions of fairness into machine learning. They found that it is extremely difficult to create systems that fully satisfy multiple definitions of fairness at once. There’s a trade-off between measures of fairness, and the relative importance of each measure must be balanced. It’s easy to overlook that “fairness” means different things in different disciplines and use cases. People need to be cognisant that we are dealing with a multi-disciplinary, inclusive basis when designing and making technology.
2. Computers, in effect, teach themselves bias as seen in a Science Magazine study that found a computer teaching itself English had become prejudiced against black Americans and women.
3. Who trained your AI? Researchers have used the Enron emails specifically to analyze gender bias and power dynamics. In other words, the most popular email data set for training AI has also been recognized by researchers as something that’s useful for studying misogyny, and our machines may be learning to display the same toxic masculinity as the Enron execs.
Who trained your AI?
Point #3 is probably most interesting to my e-discovery industry readers who now compose almost one-half of my readership base so let me take that one first.
AI systems are often built in ways that unintentionally reflect larger societal prejudices, and one reason for that is because in order for these smart machines to learn, they must first be fed large sets of data. And it’s humans, with all their own biases, who are doing the feeding. But it turns out that it’s not just individuals’ biases that are causing these systems to become bigoted; it’s also a matter of what data is legally available to teams building AI systems to feed their thinking machines. And AI data sets may have a serious copyright problem that exacerbates the bias problem.
There are two main ways of acquiring data to build AI systems:
- One requires constructing a platform that collects the data itself, like how people give over their personal information to Facebook for free. Facebook, for example, probably has one of the best collections in the world of information about the ways people communicate, which could be used to build an incredible natural-language AI system.
- The other way to get data to build artificial intelligence software is to buy or acquire it from somewhere else, which can lead to a whole host of problems, including trying to obfuscate the use of unlicensed data, as well as falling back on publicly available data sets that are rife with historical biases. For a very good analysis of that bias I refer you to a recent paper from Amanda Levendowski, a fellow at the NYU School of Law (click here).
When a company depends on data it didn’t collect itself, it disincentivizes the opening up of AI systems for scrutiny since it would mean that if companies are making their AI systems smarter with unlicensed data they could be held liable. What’s more, the fact that large data sets are often copyrighted also means that data is regularly pulled from collections that are either in the public domain or else use data that’s been made public, like through WikiLeaks or in the course of an investigation, for example. Works that are in the public domain are not subject to copyright restrictions and are available for anyone to use without paying. The problem with turning to public-domain data, though, is that it is generally old, which means it may reflect the mores and biases of its time. From what books get published to what subjects doctors chose to conduct medical studies on, the history of racism and sexism in America is, in a sense, mirrored through old published data that is now available for free. And when it comes to using data sets that were leaked or released during a criminal investigation, the problem with that data is that it’s often publically available because it is so controversial and problematic.
A perfect example of this are the Enron emails, which are one of the most influential data sets for training AI systems in the world. The Enron email data set is composed of 1.6 million emails sent between Enron employees that were publicly released by the Federal Energy Regulatory Commission in 2003. They’ve become a commonly used data set for training AI systems. Even Levendowski refers to them in the article I referenced above:
If you think there might be significant biases embedded in emails sent among employees of a Texas oil-and-gas company that collapsed under federal investigation for fraud stemming from systemic, institutionalized unethical culture, you’d be right. Researchers have used the Enron emails specifically to analyze gender bias and power dynamics.” In other words, the most popular email data set for training A.I. has also been recognized by researchers as something that’s useful for studying misogyny, and our machines may be learning to display the same toxic masculinity as the Enron execs.
NOTE: several tech vendors are now taking the 20,000+ John Podesta/Hillary Clinton hacked emails that WikiLeaks published last year in a machine-readable format to create another A.I. training data set.
Teaching bias
As the use of artificial intelligence continues to spread, we have seen an increase in examples of AI systems reflecting or exacerbating societal bias, from racist facial recognition to sexist natural language processing. These biases threaten to overshadow AI’s technological gains and potential benefits. While legal and computer science scholars have analyzed many sources of bias, including the unexamined assumptions of its often-homogenous creators, flawed algorithms, and incomplete datasets, a “view-from-10,000-feet” escapes them.
Everybody on the panel … as well as audience members … said that data and AI biases are the hardest of the hard Art + Science problems our species could possibly face and will need to solve. And one delicious tidbit from a Facebook security officer in the audience: “nobody of substance at the big companies thinks of algorithms as neutral. Bias creeps in. Nobody is not aware of the risks. But a lot of people aren’t thinking hard about the world they are asking Silicon Valley to build. It’s very difficult to spot fake news and propaganda using just computer programs.”
His statement “bias creeps in” was hammered home earlier this year when I wrote about my session in Paris at Google’s EU headquarters, speaking with an AI expert who works on Google Translate. She happens to be Turkish so it is her native language. Turkish has no gender pronouns. But when she did a back propagation test using Turkish phrases, she always ended up with results like “he’s a doctor” in a gendered language. The Turkish sentence did not say whether the doctor was male or female. But the software just assumed when talking about a doctor, it’s a man. Boy, bias is subtle.
One of the most in-your-face studies was from Science magazine which found that a computer teaching itself English became prejudiced against black Americans and women. And it addresses how the basics of machine learning can work to corrupt it if unchecked.
In the Science magazine study … and this tracks much of how machine learning works … the computer used a common machine learning program to crawl through the internet, look at 840 billion words, and teach itself the definitions of those words. The program accomplishes this by looking for how often certain words appear in the same sentence. Take the word “bottle.” The computer begins to understand what the word means by noticing it occurs more frequently alongside the word “container,” and also near words that connote liquids like “water” or “milk.”
This idea to teach robots English actually comes from cognitive science and its understanding of how children learn language. How frequently two words appear together is the first clue we get to deciphering their meaning. In the Science study, once the computer amassed its vocabulary, the researchers ran it through a version of the implicit association test, or IAT. In humans, the IAT is meant to undercover subtle biases in the brain by seeing how long it takes people to associate words. A person might quickly connect the words “male” and “engineer.” But if a person lags on associating “woman” and “engineer,” it’s a demonstration that those two terms are not closely associated in the mind, implying bias. (There are some reliability issues with the IAT in humans but I will skip that).
Here, instead at looking at the lag time, the researchers looked at how closely the computer thought two terms were related. They found that African-American names in the program were less associated with the word “pleasant” than white names. And female names were more associated with words relating to family than male names. (In a weird way, the IAT might be better suited for use on computer programs than for humans, because humans answer its questions inconsistently, while a computer will yield the same answer every single time.)
Like a child, a computer builds its vocabulary through how often terms appear together. On the internet, African-American names are more likely to be surrounded by words that connote unpleasantness. That’s not because African Americans are unpleasant. It’s because people on the internet say awful things. And it leaves an impression on our young AI.
This problem can, obviously, be enormous. During a coffee break, one attendee told me about how certain job recruiters (she named names) are relying on machine learning programs to take a first pass at résumés. But left unchecked, these programs are learning and acting upon gender stereotypes in their decision-making.
Ok, so this stuff is multi-disciplinary. An impossible task? Are these programs poisoned forever?
Inevitably, machine learning programs are going to encounter historical patterns that reflect racial or gender bias. And it can be hard to draw the line between what is bias and what is just a fact about the world. Machine learning programs will pick up on the fact that most nurses throughout history have been women. They’ll realize most computer programmers are male. Nobody is suggesting we should remove this information because as one attendee said “that might actually break the software completely”.
It is going to require the most difficult thing: safeguards. And we do not have a handle on that. So it means humans using these programs will need to constantly ask, “Why am I getting these results?” and check the output of these programs for bias. They need to think hard on whether the data they are combing is reflective of historical prejudices. Everybody in the room agreed: any “best practices” of how to combat bias in AI is still being worked out and pretty far down the road. As one attendee noted “it really requires a multi-disciplinary approach. It requires a long-term research agenda for computer scientists, ethicists, sociologists, economists, psychologists, etc. But at the very least, the people who use these programs should be aware of these problems, and not take for granted that a computer can produce a less biased result than a human.”
Yep. You’ve heard it before. AI learns about how the world has been. It picks up on status quo trends. It doesn’t know how the world ought to be. That’s up to humans to decide.
FOR PART 2 PLEASE CLICK HERE